
Sebbene l’introduzione del cloud computing abbia segnato una rivoluzione nell’elaborazione, nella disponibilità e nella distribuzione dei dati, rendendoli di fatto accessibili da ogni dove e liberandoli dalle infrastrutture fisiche dell’utente finale, oggigiorno nuove tecnologie si presentano per risolvere problemi che possono insorgere in seguito a una elevata mole di traffico di dati e nel peggiore dei casi per tempi di latenza nella trasmissione elevati. Ed è qui che entrano in gioco nuove infrastrutture come: l’edge computing e il fog computing, valide alleate anche per la gestione quotidiana dell’IoT.

Indice degli argomenti
Che cos’è il fog computing?
Letteralmente tradotto dall’inglese, con il termine “fog” si identifica la “nebbia”. In ambito informatico/tecnologico, il fog computing è una infrastruttura che si intermezza tra l’edge computing e il cloud computing, quest’ultimo già ampiamente diffuso negli anni.
Una delle prime definizioni utilizzata da Flavio Bonomi nel 2012 afferma che:
“Il fog computing è una piattaforma altamente virtualizzata che offre capacità di calcolo, immagazzinamento dati e servizi di rete tra i dispositivi terminali e i tradizionali datacentre del Cloud computing. Tutto ciò, in genere, ma non esclusivamente è offerto al limitare (Edge) della rete.”
La definizione di Cisco, invece, afferma che:
Il Fog estende il Cloud per essere più vicino alle cose che producono e agiscono sui dati IoT. Questi dispositivi, chiamati Fog node, possono essere distribuiti ovunque con una connessione di rete: in una fabbrica, in cima a un palo di alimentazione, lungo un binario ferroviario, in un veicolo o su una piattaforma petrolifera. Qualsiasi dispositivo con elaborazione, archiviazione e connettività di rete può essere un fog node.
Tra le ultime, invece, ritroviamo quella del professor Mung Chiang elaborata nel 2016, per la quale:
“Il fog è un’architettura che usa uno o molti dispositivi utente, o situati vicini all’utente al limitare della rete, per eseguire una quantità sostanziale di operazioni di immagazzinamento dati, comunicazione e gestione.”
L’utilizzo di queste tecnologie consente attraverso l’elaborazione dei dati con delle risorse di computing locali di limitare l’enorme traffico dei dati generato, ad esempio, da dispositivi di Internet of Thing (IoT), permettendo così di accedere e memorizzare sui data center remoti solo le informazioni finali. In questo modo, si riducono i tempi di risposta per ottenere i dati da utilizzare e si risolvono a prescindere problemi di latenza dovuti alla instabilità o alla scarsa larghezza di banda delle connessioni internet, specialmente in luoghi dove il digital divide è ancora ben presente.
Gli elementi fondamentali che reggono questa infrastruttura sono la disponibilità di smart device o server di prossimità capaci di elaborare velocemente i dati in modo da consentire alle risorse che ne avevano fatto richiesta di proseguire anche in una elaborazione più complessa o di disporre di dati in real-time. I risultati ottenuti, sono poi pronti, attraverso i nodi del fog computing, per essere trasmessi all’infrastruttura cloud o disponibili per essere memorizzati nei propri data center.
Fog computing, edge computing, Internet of Things (IoT)
Il fog computing, a differenza dell’edge computing, ha una topologia di rete più complessa ed è capace di gestire oltre alle prestazioni di elaborazione anche: il networking, il controllo e l’immagazzinamento dei dati (archiviazione) in cloud. L’edge computing è un modello di calcolo distribuito che si occupa di elaborare i dati il più vicino possibile alla sorgente dove i dati vengono generati. Spesso le due infrastrutture vengono erroneamente assimilate, ma in realtà non è così.
Per Internet of Things si intendono tutti quei dispositivi o smart device che connessi ad una rete internet sono capaci di dialogare tra di loro, scambiandosi informazioni ed elaborandole, per offrirci una user experience migliore nella vita quotidiana. Vengono definiti smart object, e possiamo identificare in questa categoria, ad esempio: dispositivi per la gestione dell’abitazione, elettrodomestici intelligenti e perfino oggetti wearable che monitorano le nostre attività sportive o le nostre abitudini alimentari. Lo stesso concetto si può estendere anche ai sensori di impianti industriali. La caratteristica che tutti questi oggetti hanno in comune è di produrre una continua mole di dati che ha bisogno di essere elaborata per poter permettere al dispositivo di lavorare correttamente per ottenere i risultati desiderati. Infatti, basti pensare alla continua crescita dei dispositivi mobili, come mostrata in una presentazione, alla “2020 IEEE International Conference on Fog Computing – ICFC2020”, fino a toccare secondo le previsioni oltre 10 miliardi di dispositivi nel 2022.
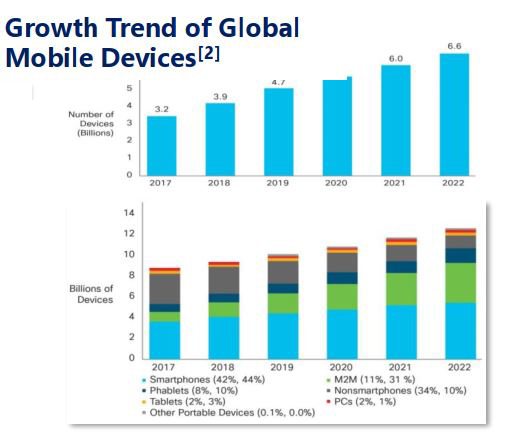
Figura 1- Growth Trend of Global Mobile Devices – ICFC2020
Che cosa fa il fog computing
Il fog computing controlla: le prestazioni, la latenza e l’efficienza, scegliendo cosa gestire nei suoi “Fog Node” e cosa invece inoltrare direttamente al cloud, effettuando delle valutazioni in base allo stato della rete. In pratica, nel suo algoritmo decisionale tiene conto di tutti quei fattori che possono influenzare il corretto funzionamento della rete o una eventuale congestione, come: la larghezza di banda dei collegamenti, la capacità di archiviazione, la gestione di eventi di guasto o perfino minacce alla sicurezza.
Quali sono i vantaggi del fog computing
Dall’Open Fog Reference Architecture for Fog Compunting possiamo affermare che le architetture Open Fog, con i loro nodi Cloud-Fog e Fog-Fog, offrono diversi vantaggi riassunti con la sigla SCALE: Security, Cognition, Agility,Latency and Efficiency. Ma vediamo nel dettaglio di cosa stiamo parlando e cosa questa infrastruttura è capace di offrire:
- Security: Sicurezza aggiuntiva per garantire transazioni sicure e affidabili.
- Cognition: Consapevolezza degli obiettivi incentrati sul cliente per consentire l’autonomia.
- Agility: -innovazione rapida e scalabilità economica nell’ambito di una infrastruttura comune
- Latency: Elaborazione in tempo reale e controllo del sistema cyber-fisico.
- Efficiency: Pooling dinamico delle risorse locali inutilizzate da dispositivi degli utenti finali partecipanti.
In conclusione, i principali vantaggi sulla rete, così come definiti dalle linee guida, sono: la garanzia di maggiore sicurezza e cognizione, con il miglioramento dell’agilità e dell’efficienza e la riduzione della latenza.
OpenFog Consortium: che cos’è, di cosa si occupa
L’OpenFog Consortium fu fondato nel novembre 2015 da un raggruppamento di grosse aziende e istituzioni, e nello specifico da: ARM, Cisco, Dell, Intel, Microsoft e Università di Princeton.
Il consorzio nasce con lo scopo di definire una architettura per affrontare le nuove sfide sulle infrastrutture e la connettività, dato che avevano già previsto che da solo il cloud non avrebbe potuto sostenere a lungo la velocità di scambio dei dati prevista e soprattutto il volume dei dati generato dall’IoT.
Tutto quanto predisposto dal consorzio può essere approfondito nelle pubblicazioni OpenFog Reference Architecture for Fog Computing e nelle documentazioni dei congressi internazionali organizzati. L’ultimo si è tenuto a Sidney nell’aprile 2020.

Ambiti di applicazione
Sempre più diffusa l’utilizzo di questa infrastruttura nell’ambito dell’IoT (Internet of Things) e dell’IIoT (Industrial Internet of Things). In particolar modo, in ciascun settore o risorsa che abbia la necessità di trasmettere ed elaborare dei dati real-time provenienti da attuatori e sensori di ogni tipo, come quelli di pressione o di flusso o da valvole di controllo. In questi casi la velocità nella disponibilità dei dati è un elemento fondamentale per il corretto funzionamento di un impianto, o una risorsa in generale, e per prevenire anomalie, guasti e conseguenti perdite economiche ingenti.
Altri esempi più specifici di applicazione di questa infrastruttura, sono nella gestione di:
- Settore dei trasporti con smart car e il controllo del traffico. In questo caso, un fog node è rappresentato da un veicolo che può essere oltre ad una automobile, anche: una nave, una imbarcazione, un treno, un camion, un drone, un autobus, etc.
- Settore della sicurezza e videosorveglianza, con dispositivi installati in luoghi pubblici o privati. Basta tenere conto che le telecamere possono generare una quantità enorme di dati da elaborare, che possono superare anche l’ordine dei terabyte al giorno per ogni singolo dispositivo, in base alle loro impostazioni e alla risoluzione di acquisizione del segnale audio/video.
- Smart cities, smart home, negozi, aziende manifatturiere o imprese generiche. Anche in questo caso, si ricorre sempre di più all’utilizzo di sensori per monitorare l’andamento quotidiano e soprattutto la sicurezza da accessi non autorizzati. Nelle smart cities questa tecnologia risulta utile per prevenire la congestione del traffico, garantire la sicurezza pubblica, ottimizzare il consumo di energia elettrica e dei servizi pubblici e per ultimo, ma non meno importante, offrire una connessione pubblica alla rete internet. Di conseguenza, in una smart city si potrebbero poi gestire tutte le strutture in maniera intelligente, come: ospedali, parcheggi, fabbriche, sistemi autostradali o di viabilità.
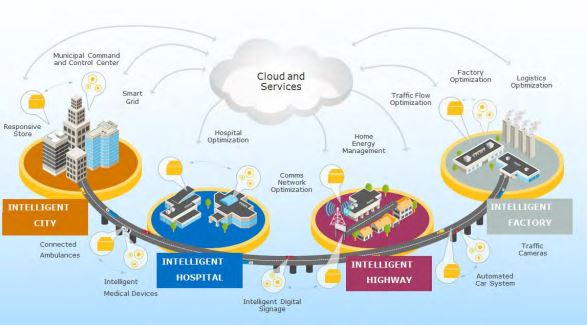
Figura 2- Opportunities for smart cities – OpenFog Reference Architecture for Fog Computing
- Smart building. Negli edifici intelligenti la rete può essere utilizzata per gestire il traffico di molteplici sensori che rilevano i parametri di funzionamento dell’edificio, come: la temperatura, l’umidità, il controllo di apertura e chiusura porte, gli ascensori e perfino la qualità dell’aria.
Questi sono solo alcuni degli ambiti in cui il fog computing trova applicazione sia in ambito domestico sia in ambito industriale.
I dati sono ovunque intorno a noi e vengono generati di continuo dei dispositivi che ci circondano, ed è sempre più importante poterli gestire per semplificare le nostre abitudini quotidiane e lavorative. Nel 2016 è stato stimato che una persona in media al giorno crea circa 650 MB di dati al giorno, e per alcuni progetti si prevedeva che si sarebbero generati più del doppio dei dati, entro l’anno corrente.
Concludiamo, citando una definizione dal documento OpenFog Reference Architecture for fog computing, che riassume l’importanza della gestione di questi Big Data, con una sigla DIKW – Data Information Knowledge Wisdom. Cosa vuol dire? I Dati raccolti diventano Informazione, e quando sono memorizzati e accessibili diventano Conoscenza. La conoscenza permette la Sapienza per un sistema IoT autonomo.
Articolo originariamente pubblicato il 09 Ott 2020






