
Nell’articolo dedicato a “From Data to Value”: un modello per caratterizzare le offerte prodotto-servizio data-driven è stato affrontato il tema di come, grazie alla disponibilità di prodotti e piattaforme intelligenti, sia oggi possibile (anche) per le aziende manifatturiere sviluppare nuove offerte integrate di prodotti e servizi “data driven”, definite come DDPSS (i.e. “Data-Driven Product Service Systems” – DDPSS). Si tratta di nuove offerte dove la fonte di valore per il cliente risiede proprio nella capacità dell’azienda di raccogliere, condividere ed elaborare dati trasformandoli in servizi avanzati a valore aggiunto. Nell’articolo veniva presentato un innovativo framework in grado di caratterizzare e formalizzare i DDPSS lungo quattro dimensioni.
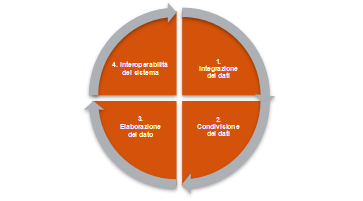
Tale modello è stato sviluppato dai ricercatori di ASAP durante la ricerca “From data to value”. In questo articolo presentiamo ora i risultati dell’applicazione di questo modello alle 7 aziende che hanno preso parte alla ricerca. Questa applicazione fornisce quindi un quadro dell’attuale livello di comprensione e maturità di queste aziende rispetto al DDPSS e mostra come il modello proposto possa essere utilizzato dai manager come utile strumento in grado di guidare lo sviluppo di queste nuove offerte.
Indice degli argomenti
Integrazione dei dati come presupposto del percorso “From Data to Value”
Essere in grado di raccogliere ed integrare dati da diversi fonti costituisce un’importante fonte di valore in quanto permette di creare quei dataset contenenti valori ed attributi indispensabili per caratterizzare al meglio fenomeni, operazioni, problemi, ecc. Oltre a ciò permette al service provider di entrare nella realtà del cliente e sviluppare nuovi servizi che non sono solo quelli rivolti al prodotto stesso. Nonostante l’evidente valore che le aziende ne possono derivare, l’analisi del campione dice che in media solo alcune categorie di dati – quelli legati al prodotto e alle operations – sono integrate.
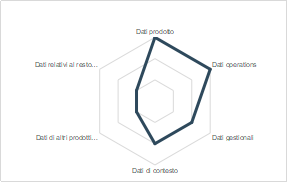
Il campione in generale ha iniziative in corso, in fase avanzata, sia sulla raccolta dei dati relativi ai proprio prodotti – stato di salute, disponibilità pezzi di ricambio e consumabili, locazione guasti, ecc. – e alle operations – tempi operativi, esecuzione attività sul prodotto, assegnazione task operatori, ecc – utilizzati per il controllo ed il monitoraggio, mediante l’elaborazione di appositi KPI (per es. OEE) e per erogare servizi proattivi, reattivi e/o preventivi per la gestione e manutenzione di prodotto. Tale tipo di servizi, se combinati con dati gestionali e di contesto (temperature, condizioni meteo, peso materiale movimentato, ecc.), permette di ottimizzare al meglio gli interventi sul campo da parte degli operatori: si pensi ad una schedulazione dinamica degli interventi di campo che considerando le condizioni esterne (es. presenza o meno di pioggia), della disponibilità degli operatori (i.e. che da gestionale risultano avere le adeguate competenze) e del cliente permettono una migliore allocazione temporale dei task (es. intervento manutentivo su macchina di spostamento terra). Se per la maggior parte delle aziende del campione le iniziative per l’integrazione di questi dati sono in fase progettuale o parzialmente avviate, quelle per l’integrazione di dati di prodotti simili (i.e. dati di prodotti di modelli diversi e/o di altri brand ma simili) o provenienti dal resto del sistema produttivo del cliente (es. pompe ausiliare dell’impianto di raffreddamento dell’impianto cogenerativo installato) non sono state avviate oppure solo pensate ma non attuate.
L’integrazione dei dati da diverse fonti consente così di poter elaborare informazioni più complete, ricche di attributi che consentono l’operatore o sistemi automatizzati intelligenti di correlare tra loro le diverse occorrenze e risalire alla radice dei problemi. Questo per l’OEM porta al grosso vantaggio di migliorare le prestazioni di prodotto sia in fase di progettazione e che di attività del prodotto, permettendo di agire preventivamente per garantire l’up-time e così garantire al cliente – in fase di definizione del contratto – soluzioni personalizzate e di pay-per-use, oltre a poter includere nuovi servizi nel proprio portfolio.
Al cliente può essere fornito (attraverso per esempio a un portale), una dashboard completa con i KPI che gli consente di controllare e monitorare il suo parco macchine, effettuando se necessario analisi di benchmarking delle prestazioni.
Condivisione: dai dati dati al valore insieme a partner e clienti
Dall’analisi della dimensione di condivisione dati, emerge fortemente come ci sia l’interesse verso la raccolta dei dati degli altri attori, ma come ci sia anche un freno nel verso contrario, ovvero nel condividere un dato di proprietà. Infatti, non tutto il campione riesce ad avere visibilità dei dati del cliente, e pochissimi di loro, una volta ottenuti questi dati, stanno lavorando per darne visibilità ad altri attori del network, sia interni che esterni.
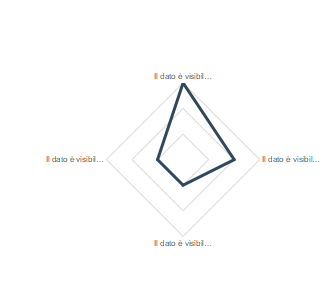
Come si può notare dal grafico, gran parte del campione ha strutturato delle piattaforme front-end di visualizzazione dati e informazioni per il cliente. Nonostante ciò, non sempre tutti i dati sono disponibili al cliente, infatti spesso esistono livelli di accesso al dato, che definiscono rispetto a politiche di visualizzazione per utenti o rispetto al contratto di vendita. Non tutti gli OEM hanno comunque piena visibilità sui dati, infatti alcuni clienti non consento che questi ne abbiano accesso, soprattutto nel caso in cui i dati sono correlati alla sfera economica. Per quanto riguarda poi la condivisione dei dati con altri attori, si può notare come alcune aziende siano ben strutturate per la condivisione dei dati all’interno del proprio network, considerando ad esempio personale di manutenzione, nonostante ciò, in generale il campione rimane ancora ad un livello in cui il dato non è condiviso. Infine, le aperture verso provider esterni, al fine di abilitarli nell’erogazione di servizi sui dati raccolti sono invece ancora poco diffuse.
Considerando la dimensione di condivisione dati, la comprensione dei benefici dovuti al raggiungimento della maturità sulle diverse categorie è immediata. Avere visibilità sui dati all’interno del network permette ai provider di soluzioni di cambiare il proprio approccio verso il cliente da reattivo a proattivo, migliorare la programmazione e la gestione degli interventi (di manutenzione, fornitura, ecc.) ed efficientare il processo decisionale in termini di tempo e costi, oltre che a sostenere nuovi modelli di business (e.g. pay per use, pay per result). A ciò si deve aggiungere la possibilità di outsourcing delle attività tecniche e servizi complementari a service provider esterni, o la co-progettazione dei servizi con questi altri fornitori, possibilità che comportano anche benefici in termini di «effetti di rete» dovuti alla presenza di più attori nel network.
Per quanto riguarda il cliente, chiaramente questo potrà beneficiare di tutto ciò che il provider riesce a sostenere, quindi ad esempio l’accesso a servizi proattivi, migliori capacità di risposta e intervento, ma anche alla condivisione del rischio nel momento in cui si attivano nuovi modelli di business. Inoltre, condividendo il dato con l’OEM, il cliente può beneficiare del know-how di prodotto e servizio che si traduce in analisi del dato più affidabili e analisi prescrittive.
Elaborazione: la trasformazione dei dati in informazione e conoscenza
Il dato da solo non costituisce un’informazione: è necessario un processo di elaborazione in grado di trasformarlo in informazione e conoscenza utile per l’azienda. Tale processo, che deve essere progettato e gestito mantenendo un focus costante sui bisogni dell’utilizzatore, può essere affrontato in diversi modi, attraverso un back-end strutturato, analisi manuali e/o automatizzate.
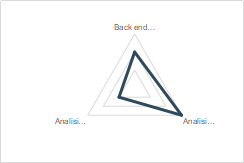
Dall’analisi del campione emerge come le analisi manuali siano applicate in modo generalizzato: di fatto si può dire che i fogli di calcolo (es. Excel) siano lo strumento di base più diffuso per elaborare i dati per via della loro semplicità di utilizzo e, soprattutto, della loro diffusione (i.e. adozione standard nella quasi totalità dei PC aziendali). Gli esperti di impianto e processo, a partire da estrazioni dedicate dalla piattaforma che utilizzano per la raccolta dati dal campo, sono così in grado in autonomia di effettuare le analisi di cui hanno bisogno per la risoluzione della maggior parte dei problemi del cliente. Rarissimi sono invece i casi di aziende che hanno già avviato progetti per realizzare tali analisi in modo automatico, per mezzo di appropriati algoritmi rule-based o intelligenti (di machine learning), principalmente a causa della mancanza di un’adeguata base dati sia in termini di storico disponibile che per la loro scarsa qualità (i.e. dati sporchi, non consolidati, ecc.); ed in generale consci delle varie soluzioni che il mercato offre, soprattutto le principali PaaS (es. Amazon AWS, Azure, IBM Cloud) per poter scalare senza problemi le elaborazioni anche su grandi quantità di dati simultaneamente e all’occorrenza, favorendo l’azione in termini predittivi e/o prescrittivi. Parte delle aziende del campione è comunque dotata (o si sta dotando) di un back-end strutturato: anziché lasciare l’elaborazione dati ed il supporto al cliente in mano al singolo operatore, l’OEM/service provider mette a disposizione un intero team composto da persone con diverse esperienze e competenze (data scientist, ingegneri, tecnici, ecc.) che, dotati di opportuni tool, è in grado di supportare al meglio il cliente.
Per l’OEM/service provider, disporre di una buona capacità di elaborazione dei dati consente non solo di migliorare l’efficacia e l’efficienza del processo decisionale, ma permette anche di “scavare” all’interno dei dati a disposizione per estrarre informazioni e valore: profilare i clienti (analisi utilizzo dei prodotti, confronto con dati contestuali, ecc.), migliore programmazione e gestione degli interventi (di manutenzione, fornitura, ecc.) passando dall’agire non in modo reattivo ma proattivo e preventivo, automatizzare i processi operativi con conseguente risparmio di risorse. Il cliente può così beneficiare del know-how del service provider/ produttore, migliori capacità di risposta e intervento, accedere ad analisi customizzate.
Interoperabilità di sistema
Per quanto riguarda le modalità di interazione della soluzione proposta con altri sistemi, si può notare che la maggior parte delle aziende è attiva sull’interoperabilità informativa, che considera quindi un passaggio di informazioni soprattutto verso i sistemi gestionali del cliente e viceversa. Poche aziende hanno intrapreso percorsi di interoperabilità transazionale, sebbene questi abilitino l’interazione con altri sistemi senza una vera e propria condivisione di dati. Da ultimo la categoria meno sviluppata è quella dell’interoperabilità progettuale, che vedrebbe il coinvolgimento di più attori per la realizzazione delle soluzioni.
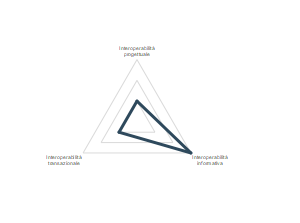
Dal grafico si può notare come solo poche delle soluzioni implementate dalle aziende partecipanti abilitano il passaggio di trigger verso altri sistemi, sia del cliente che esterni, generando dei “comandi” che fanno azionare altri processi, come ad esempio il riordino di spare parts o l’intervento di un tecnico di campo. L’ interoperabilità informativa è invece fortemente diffusa con i sistemi informativi del cliente, abilitando la possibilità di raccogliere dati gestionali e restituire dati utili per il cliente; più raramente invece questi flussi sono esportati verso altri partner. La collaborazione progettuale con altri attori del network non è invece facile per diverse ragioni, come ad esempio la fiducia e sicurezza nella condivisione dei dati e delle informazioni, soprattutto in quei contesti in cui i progetti richiedono mettere a comune know-how molto specifico che comprende anche diritti di copyright.
I benefici legati all’interoperabilità del sistema sono vari, sia per i provider che per i clienti finali. Per quanto riguarda i provider l’interoperabilità consente di gestire flussi di informazioni provenienti da sistemi diversi, senza replicarli. Si accede anche alla possibilità di automatizzare processi operativi o dare inizio a determinate azioni. Nel caso di interoperabilità transazionale, uno dei benefici maggiori è la possibilità di non condividere del dato in sé, ma abilitare solo la comunicazione di informazioni o segnali.
La possibilità di co-progettare le soluzioni insieme ad altri partner e ai clienti apre invece la possibilità di personalizzazione o di definizione di nuove soluzioni. L’interoperabilità abilita il cliente ad accedere ad informazioni e servizi con un’unica interfaccia, di collegare sistemi sviluppati in-house e automatizzare processi aziendali già presenti. Ancora una volta si presentano anche gli effetti di rete e la così detta “API economy”, fenomeni in cui presenza di più attori nel network porta potenziali benefici a tutti, infatti, più servizi ed API saranno disponibili, più clienti probabilmente adotteranno quel sistema e allo stesso modo, più potenziali acquirenti si delineano, più partner saranno interessati a far parte dell’ecosistema.
I risultati di questa ricerca sono stati recentemente presentati nell’evento organizzato da ASAP dove i manager delle aziende che hanno preso parte allo studio hanno raccontato i casi di successo, illustrando sfide, opportunità e vantaggi dei servizi data driven. Se vuoi saperne di più contatta QUI gli autori di questo articolo.
Immagine fornita da Shutterstock.



