
La predictive maintenance (diversa dalla c.d. manutenzione predittiva) è una strategia di approccio alla manutenzione che si fonda sull’individuazione anticipata del deterioramento delle condizioni di un asset industriale (data-driven) basata sui dati che la macchina stessa produce nel corso del suo funzionamento reale. Grazie a tale approccio si è in grado di determinare se è effettivamente necessario schedulare un intervento manutentivo, evitando sia i downtime che le manutenzioni inutili.
Indice degli argomenti
Predictive maintenance, l’apporto del machine learning
Secondo studi di settore, solo il 18% delle cause dei fault di un’apparecchiatura industriale è correlato all’età dell’asset, mentre il restante 82% dei fermi/guasti si verifica in modo casuale. Ciò significa che la massima parte del rischio di fault non è dovuta dall’età dell’asset e, pertanto, risulta evidente come la manutenzione preventiva rappresenti una strategia inefficace e inutilmente dispendiosa. È evidente, infatti, che quando si allocano risorse ad asset che non necessitano immediatamente di manutenzione si sprecano ore lavorative e si utilizzano componenti non realmente necessari, aumentando i costi. A sostegno di ciò, uno studio di Oniqua Enterprise Analytics afferma che il 30% delle attività di manutenzione viene svolto troppo frequentemente e tale pratica rappresenterebbe il principale fattore trainante degli sprechi.
Il corretto equilibrio tra investimenti nella manutenzione e beni affidabili richiede un approccio più moderno.
La Condition-based maintenance è un approccio che basa le decisioni inerenti gli interventi manutentivi in funzione delle necessità effettive, le quali sono determinate attraverso il monitoraggio delle condizioni delle risorse.
In funzione di quanto detto solo un cambiamento nelle condizioni e/o nelle prestazioni di una macchina industriale, anche se non visibile a occhio umano, può (e deve) essere la ragione principale per eseguire la manutenzione; peraltro, la manutenzione preventiva basata sull’età può altresì compromettere la stabilità e, addirittura, introdurre guasti in un sistema ben funzionante.
L’approccio corretto è, dunque, quello basato sui dati; per questo motivo il machine learning, termine con il quale ci si riferisce in modo generico alle tecnologie di apprendimento automatico, si rivela uno degli strumenti migliori allo scopo.
Si riporta qui uno use case di applicazione delle tecniche di manutenzione predittiva basata su machine learning realizzato dall’azienda 40Factory S.r.l per un costruttore italiano di linee per lavorazione della lamiera nel mondo del bianco il quale vanta tra i suoi clienti le più grandi aziende multinazionali del settore, aziende alle quali un siffatto approccio viene offerto come servizio nell’ottica di un processo di servitizzazione del prodotto.
Predictive maintenance, un esempio per capire come si attua
Le macchine costruite dalla suddetta azienda sono definibili come sistemi ad alta tecnologia in quanto formati da un insieme di componenti idraulici, meccanici, laser e altri. In questo caso, la complessità del sistema industriale rendeva antieconomico ed eccessivamente complesso realizzare modelli di manutenzione predittiva basati sulla pura competenza/conoscenza ingegneristica a priori del comportamento delle singole componenti. Un simile approccio, inoltre, andrebbe ripetuto per ogni singolo componente, rendendo il modello di business difficilmente scalabile.
D’altro canto, avvalersi di un modello di machine learning consente di utilizzare un approccio unitario per diversi componenti, garantendo al contempo un’elevata precisione nella predizione nonché la possibilità di ottenere un miglioramento continuo del modello grazie alla raccolta di nuovi dati.
Concettualmente l’approccio illustrato si basa sui seguenti step:
- acquisizione dei dati
In prima battuta occorre definire quali sono le variabili da raccogliere.
Tipicamente un sistema industriale moderno ha già a disposizione tutti i dati necessari per la sua diagnostica; in particolare, in tale ambito si fa riferimento a coppie, temperature, pressioni ecc. Naturalmente, ogni componente avrà dati specifici legati alla sua natura e al suo funzionamento i quali verranno campionati ad altra frequenza per diversi cicli di lavoro in condizioni ottimali (quindi quando la macchina è nuova e validata). Nel caso l’automazione non disponga dei dati necessari, occorre prevedere l’aggiunta di sensoristica specifica.
- anomaly detection
Una volta acquisiti sufficienti dati, viene allenato il c.d. modello di machine learning.
I modelli utilizzati sono detti modelli di anomaly detection (anche detti classificatore a singola classe). Il concetto sul quale si fonda il funzionamento dell’algoritmo è di facile comprensione: il modello apprende la “normalità” (ossia una serie di variabili rappresentanti, ad esempio, cicli di lavoro in condizioni normali) da un set di dati e, una volta che l’asset è operante in un contesto produttivo, è in grado di riconosce quanto i dati attuali, descrittivi del funzionamento della macchina, si stiano discostando dalla normalità. Se il discostamento è eccessivo, ossia se questo supera una certa soglia prestabilita, significa che i dati raccolti in quel momento sono anomali e l’utente viene allertato.
L’anomalia, in questo caso, non rappresenta l’effettivo fault, ma è una condizione in cui la macchina sta lavorando in maniera sub-ottimale e probabilmente andrà incontro a malfunzionamenti nel futuro prossimo.
La vera efficacia di un modello di questo genere è determinata da quanto esso sia in grado di comprendere nel dettaglio i dati. Per questo motivo vengono utilizzati modelli di deep learning ricorrenti, trattasi di reti neurali che non solo capisco la relazione tra le variabili, ma anche la loro evoluzione temporale attesa. Per fare un esempio: un modello di anomaly detection basato su reti neurali riconoscerà che un certo valore di corrente è anomalo in relazione a quello che stanno facendo tutte le altre variabili in un certo momento della produzione. Lo stesso valore di corrente, in un altro momento e in altre condizioni, potrebbe essere perfettamente normale.
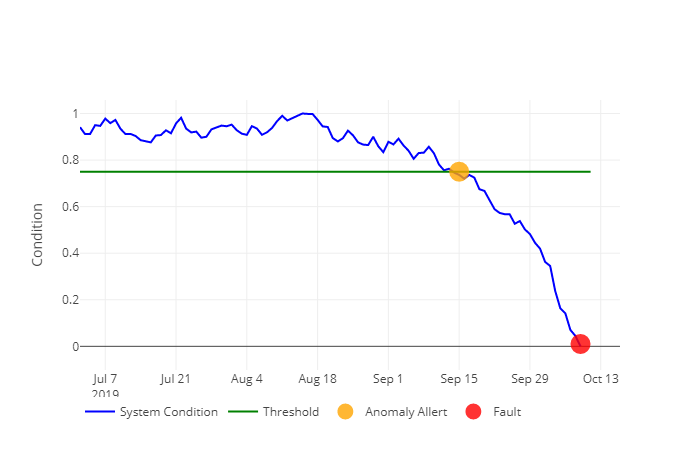
Figura 1: Esempio di trend della condizione di un asset. L’anomalia anticipa nel tempo il fault, dando tempo all’utilizzatore di intervenire sull’asset.
- classificazione
Superata la fase di “training”, il modello viene messo in produzione e, durante la vita dell’asset, raccoglie nuove anomalie e problematiche e le segnala all’utente. In queste condizioni il sistema, però, è ancora limitato: esso, infatti, è in grado di informare l’utente che qualcosa non va, ma non che cosa non va.
Per questo motivo, ogni qual volta un’anomalia viene riscontrata viene salvata in modo tale da poter essere studiata dagli esperti del sistema.
Raccolte un certo numero di anomalie, un altro modello, detto di classificazione, si occuperà di classificare l’anomalia in corso nel sistema in modo da fornire una diagnosi precisa del malfunzionamento che presumibilmente si verificherà nel prossimo futuro. Da sottolineare è il fatto che ogniqualvolta che il sistema individua un’anomalia mai riscontrata, esso sarà in grado di riconoscere la novità creando una nuova categoria di anomalie che potrà essere studiata e “taggata” dalle figure preposte. In tal modo, una volta che un simile comportamento anomalo si ripeterà, il sistema sarà in grado di riconoscerlo e ricondurlo ad una determinata classe.
L’utilità e la potenza di un siffatto sistema è data dal fatto che più anomalie si raccolgono, più cresce l’esperienza del sistema che diventerà sempre più abile a indicare all’utente (tramite dashboard dedicate) informazioni corrette e approfondite circa gli eventi che potranno verificarsi.
- condivisione
Facendo specifico riferimento alle linee sulle quali è stato sviluppato il sistema illustrato, esse sono composte da moduli che vengono riutilizzati su diversi asset in diverse parti del mondo.
Grazie alla condivisione dei modelli e dell’esperienza acquisita tramite la condivisione dei dati in cloud è possibile fornire a un componente di una linea di nuova costruzione tutto il bagaglio di conoscenze inerenti le anomalie apprese dalla sua gemella dall’altra parte del mondo.
Questo aspetto fornisce alla soluzione una scalabilità esponenziale: ciascun asset connesso al cloud potrà acquisire la conoscenza di ogni anomalia riscontrata su una qualunque delle altre macchine connesse, in tal modo ognuna di esse contribuirà ad arricchire la conoscenza circa il (mal)funzionamento di ogni singolo componente.
In conclusione, l’utilizzo di tecnologie di intelligenza artificiale che consentono di studiare in modo aprioristico la relazione tra la variabilità dei dati di funzionamento di un asset consente di raggiungere due importantissimi obbiettivi: in primo luogo permettono di approfondire sensibilmente la conoscenza circa le cause di fermo che affliggono una macchina industriale, in secondo luogo determinano una riduzione sensibile del numero di fermi macchina, permettono una pianificazione smart degli interventi manutentivi in quanto basati sull’effettiva necessità e, infine, semplificano l’approvvigionamento dei ricambi e la gestione dei magazzini, il tutto in un’ottica lean.




