
Indice degli argomenti
La traiettoria evolutiva dei sistemi informativi – Premessa
Nell’epoca della trasformazione digitale, un tema di importanza centrale per le imprese è la progettazione della traiettoria di evoluzione del proprio sistema informativo. Il sistema informativo esistente, ovvero l’insieme degli strumenti tecnologici ed organizzativi che l’impresa usa per organizzare i dati e veicolare le informazioni all’interno dei propri processi di business, è infatti il fondamento di qualsiasi percorso di trasformazione che si voglia intraprendere. Conoscerne la filosofia di progettazione, le ragioni alla base dell’assetto corrente ed i possibili limiti rispetto alle sfide del futuro assume fondamentale importanza per qualsiasi impresa, manifatturiera e non. Questo diviene ancora più importante in questa fase storica perché, oltre alla sfida della trasformazione digitale, vi sono alcune rilevanti discontinuità di mercato (come l’interruzione del supporto di alcuni applicativi realizzati su vecchie tecnologie) che di fatto forzano le imprese a prendere una decisione circa la direzione di evoluzione del proprio sistema informativo.
Sistemi informativi: uno sguardo agli approcci di riferimento
Tradizionalmente i sistemi informativi sono stati realizzati seguendo due possibili approcci, che nella loro antiteticità, possiamo vedere come gli estremi di un continuum di possibilità (Rashid et al., 2002, The Evolution of ERP Systems: A Historical Perspective, chapter 1).
Approccio ai sistemi informativi: la soluzione integrata
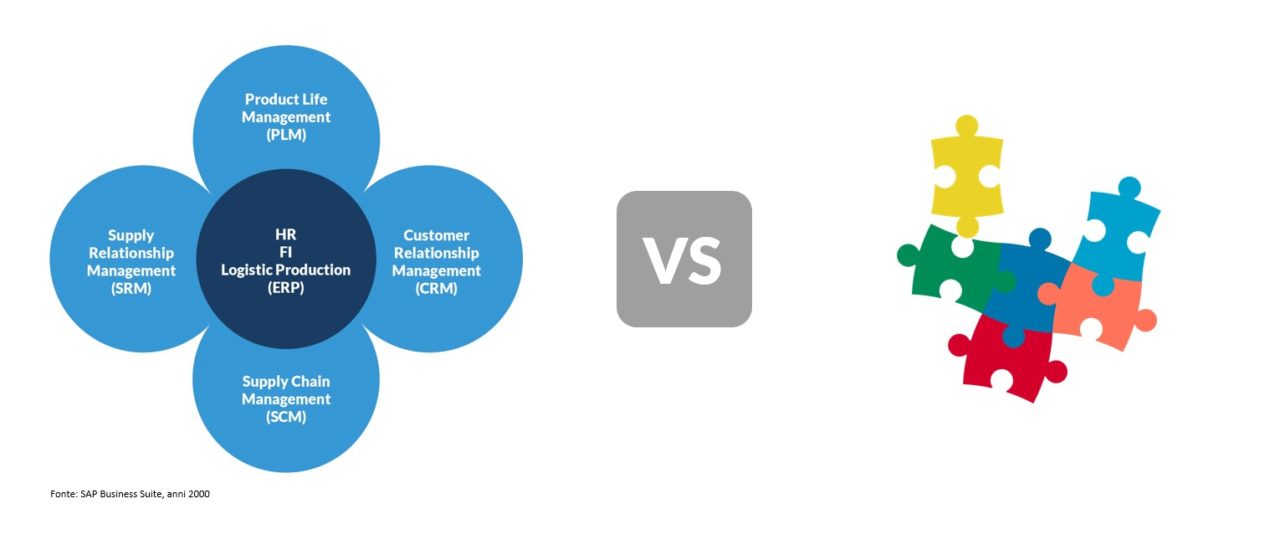
Nel primo approccio, il sistema informativo aziendale viene costruito in logica di soluzione integrata, ovvero acquistando il core ERP ed i principali moduli funzionali da uno stesso fornitore, e potendo così contare su una progettazione unita e razionale delle basi di dati, oltre che su una esperienza unificata delle interfacce applicative. Nella Figura 1 questo è il caso di sinistra, che si ispira all’approccio ERP di inizio anni 2000, con tutte le componenti classiche di un sistema informativo ben illustrate (ERP, CRM, PLM, SCM e SRM).

Scopri come riorganizzare i sistemi informativi, visitando il sito Digital Lake
Approccio ai sistemi informativi: “best of breed”
L’approccio antitetico, denominato best of breed, prevede invece che l’azienda selezioni il miglior fornitore per ciascuna specifica funzionalità applicativa; sarà onere dell’azienda stessa integrare i database sottostanti, assicurare la consistenza e la sincronia dei flussi dati, mentre i diversi utenti si troveranno a sperimentare interfacce diverse da applicazione ad applicazione, potendo però contare, per ogni ambito, sulla migliore copertura del proprio fabbisogno informativo. Il patchwork che tipicamente è richiesto nell’integrazione e nell’armonizzazione dell’esperienza utente è, con una immagine evocativa, richiamato alla destra di Figura 1.
L’esperienza comune: il modello “ibrido”
In realtà, nell’esperienza comune, la quasi totalità delle imprese ha seguito nel tempo un approccio ibrido, scegliendo in genere un sistema ERP a cui sono affiancati alcuni moduli funzionali del medesimo fornitore mentre altri moduli funzionali sono affidati ad altri fornitori, a partire da quelli più specialistici (PLM) fino a quelli più generici (SRM). Ovviamente, di settore in settore, si sono affermate delle combinazioni più ricorrenti, una sorta di Golden Teams, che hanno dimostrato sul campo la loro validità. I sistemi informativi costruiti secondo la combinazione di una di queste due logiche hanno accompagnato le imprese per oltre due decenni, dall’avvento della prima ondata di ERP-zzazione (che possiamo convenzionalmente collocare intorno alla metà degli anni 90 del secolo scorso) fino ai giorni nostri; con sistemi informativi così disegnati le imprese hanno affrontato molte sfide di crescita, internazionalizzazione, evoluzione del mix dei prodotti e dei servizi, in uno scenario di aumento generalizzato della complessità e della turbolenza della competizione, con un discreto successo.
Uno sguardo al futuro: quale evoluzione per i sistemi informativi
Appena finito di celebrare i successi della prima ondata di diffusione dei sistemi informativi, è necessario prendere atto del fatto che importanti cambiamenti di tipo tecnologico, economico, e soprattutto sociale, stanno rendendo obsoleto questo modello di (realizzazione di un) sistema informativo.
Portiamo dalle sfide tecnologiche: sull’onda della quarta rivoluzione industriale e della convergenza fisico-digitale, le imprese (manifatturiere e non) stanno abbracciando una nuova visione del proprio business in cui le tecnologie digitali entrano più profondamente nei processi operativi, e trasformano in patrimonio da valorizzare ogni dato raccolto da macchinari, operatori, sensori, prodotti e dispositivi indossabili nel corso della loro vita sul campo. L’Internet of Things (e più specificamente l’industrial IoT, se si guarda al settore industriale-manifatturiero) pone così il sistema informativo aziendale nella condizione di dover raccogliere ed elaborare enormi quantità di dati, molto diversificati nei formati e nei flussi di generazione, cosa che mette in crisi le architetture tradizionali illustrate precedentemente. Anche un approccio best of breed rischia di essere inefficace perché, ammesso che riesca a gestire la sfida della raccolta e conservazione del dato, esso rischia di separare eccessivamente il dato dalle applicazioni che potrebbero fruirne: ad esempio, si rischia di isolare il feedback di sensore di macchina dal software PLM che deve valutare la producibilità di una parte, oppure di isolare il flusso dati di un tracker di spedizione dal software di Supply Chain Planning che deve gestire il ritardo logistico, oppure si rischia di isolare il dato di un energy meter dal software che si occupa di costing accounting. Questi esempi aiutano a capire come esploderebbe la complessità di un approccio best of breed, mentre soluzioni integrate rischierebbero di assumere dimensioni, e quindi costi, inaccessibili per la stragrande maggioranza delle imprese.

L’impatto delle dinamiche competitive sui processi di business e sui sistemi informativi
La seconda sfida è rappresentata dalle dinamiche competitive e di mercato, che rimangono quelle già menzionate in precedenza (crescita, internazionalizzazione, evoluzione del mix dei prodotti e dei servizi, complessità e turbolenza della competizione) ma continuano a crescere in scala e in velocità come mai sperimentato prima d’ora. Si pensi, per fare un esempio, alla gestione della catena di fornitura: sotto la pressione rappresentata dalla continua innovazione di prodotto e dal contenimento dei costi, le imprese devono cogliere tutte le opportunità di fornitura che si possono ottenere sia da fornitori collocati nei distretti di prossimità, sia da fornitori offshore. All’ampliarsi della base dei fornitori, tuttavia, crescono le problematiche legate al processo di scouting, di certificazione, onboarding e qualificazione, di comunicazione dei target e dei piani di fornitura, al loro monitoraggio, al processo di gestione dei flussi finanziari e di gestione dei rischi che una tale disarticolata e remota catena di fornitura può portare. Da questo punto di vista, la recente esperienza della pandemia ci offre un esempio concreto di come i risultati finanziari di un’impresa possono essere profondamente influenzati dalla complessità legata alla rete di fornitura. I sistemi informativi che sono oggi deputati alla gestione di queste relazioni sono inadatti per organizzare tutti i dati esistenti e per elaborarli in tempo utile per essere utilizzati all’interno dei processi di decisione.

I sistemi informativi davanti alla sfida delle “nuove generazioni”
Una terza sfida, più sottile ma non meno importante, è rappresentata dal cambiamento nelle attitudini delle giovani generazioni, ovvero di coloro che stanno uscendo dai corsi universitari in questi anni e diventeranno il nucleo della forza lavoro dei prossimi decenni. Questo terzo aspetto si acuisce se si fa riferimento a coloro che entrano nel mondo del lavoro con buone qualifiche (i cosiddetti “giovani talenti”), che non sono più tipicamente disposti ad aspettare i lunghi tempi che sarebbero necessari per maturare la necessaria esperienza in azienda che consenta loro di interpretare dati e informazioni parziali che sono disperse attraverso sistemi e applicazioni differenti. I migliori laureati, oggi, si pongono obiettivi di carriera molto veloci, e obiettivi personali di portare un cambiamento visibile in tempo brevi: questo cambio di attitudine cozza con la tipica organizzazione dei dati e delle informazioni dei sistemi informativi esistenti, un po’ come la fatica di imparare ad usare un personal computer anni 90 cozza con l’esperienza di apprendimento e di uso di uno smartphone. Oltre a questo cambio di attitudine, forse più marcato nelle giovani generazioni, tutti noi sperimentiamo anche una evoluzione del nostro approccio alle decisioni, nel momento in cui sempre più spesso abbiamo ad interagire con applicazioni del mondo consumer che ci abituano a interfacce molto comode, che sono in grado di elaborare dati primitivi da più fonti per restituirci soltanto le informazioni che servono per decidere in autonomia. Come evocato in Figura 4, oggigiorno, se dobbiamo decidere se possiamo attardarci in una riunione o se dobbiamo congedarci per andare a prendere nostro figlio a scuola, siamo ormai abituati ad una costellazione di app che ci pre-elaborano dati da più fonti in tempo reale (traffico, timetable ufficiali e ritardo dei mezzi di trasporto, etc.) a partire dai quali noi, come decisori di ultima istanza, valutiamo rapidamente ed efficientemente cosa fare. Questo modo di vivere ed intendere il supporto dell’informatica alle nostre decisioni sta passando sempre più dalla nostra esperienza consumer alle aspettative della nostra sfera professionale.
La tradizionale architettura dei sistemi informativi: il rischio obsolescenza
Se componiamo queste tre direttrici di evoluzione, vediamo come la tradizionale architettura dei sistemi informativi sia ormai decisamente obsoleta, incapace di cogliere sia i requisiti di gestione del dato generato dalle nuove tecnologie 4.0, sia di seguire la rapidità, l’ampiezza e la complessità dei problemi di decisione imposti dal business, sia incapace di rendersi immediatamente fruibile anche a giovani generazioni di talenti che abbiano obiettivi di permanenza limitata all’interno di una organizzazione, e che siano abituati a costruire il proprio processo di decisione rafforzandolo con un continuo ricorso ad app specializzate.
Per approfondire il tema del valore dei dati per le imprese vai al sito dedicato al Digital Lake
Quale nuova architettura per il sistema informativo di un’azienda? Un esempio per capire meglio….
Come dovrà dunque essere architettato oggi il sistema informativo di un’azienda (manifatturiera e non) che possa dirsi a prova di futuro? Ad aiutarci nel dare una risposta a questa domanda viene in soccorso l’esempio rappresentato in Figura 5, e che illustra (ad un livello molto elevato) l’architettura alla base del sistema che sta dietro al dispositivo digitale al centro della nostra esperienza consumer, ovvero lo smartphone.
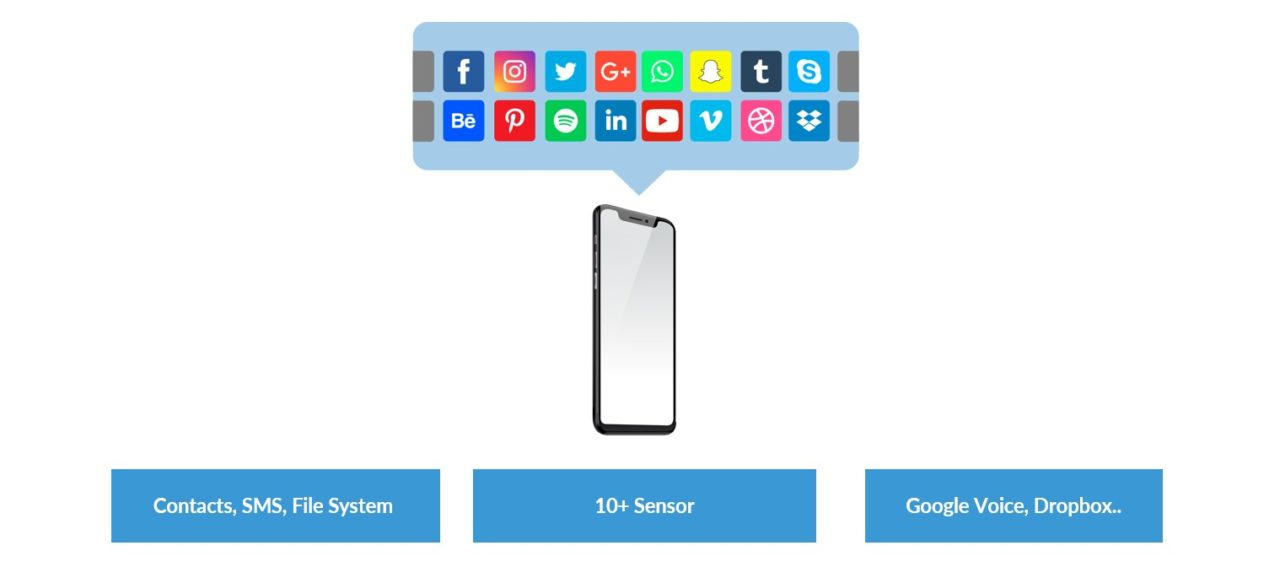
Uno smartphone moderno è una piattaforma attraverso la quale
1) possiamo avere accesso a delle risorse (di memoria, di computazione) che sono all’interno del device stesso,
2) possiamo avere accesso a dati relativi alla nostra interazione con il mondo fisico numerosi diversi sensori e
3) possiamo avere accesso a servizi e componenti di software che sono disponibili nel cloud.
Questa architettura include (al livello corretto) anche tutti gli strumenti con cui si possono sviluppare le applicazioni che, progettate con criteri di altissima usabilità ma soprattutto mirando a cogliere un chiaro bisogno decisionale dell’utente, valorizzano i dati disponibili, li trasformano in informazione e quindi supportano la libera decisione dell’utente. L’architettura dello Smartphone, se non altro per il successo e la familiarità che già abbiamo con essa, è chiaramente il modello a cui dobbiamo ispirarci per la progettazione del sistema informativo del futuro.
Guidati da questa analogia, proviamo ad immaginare come potrebbe funzionare il supporto decisionale dato dal sistema informativo del futuro di fronte a uno problema di decisione altamente complesso, come ad esempio quello della valutazione del rischio che si crea nella catena del valore di un’azienda nel momento in cui essa attivi una relazione con un nuovo fornitore mai utilizzato prima di allora.
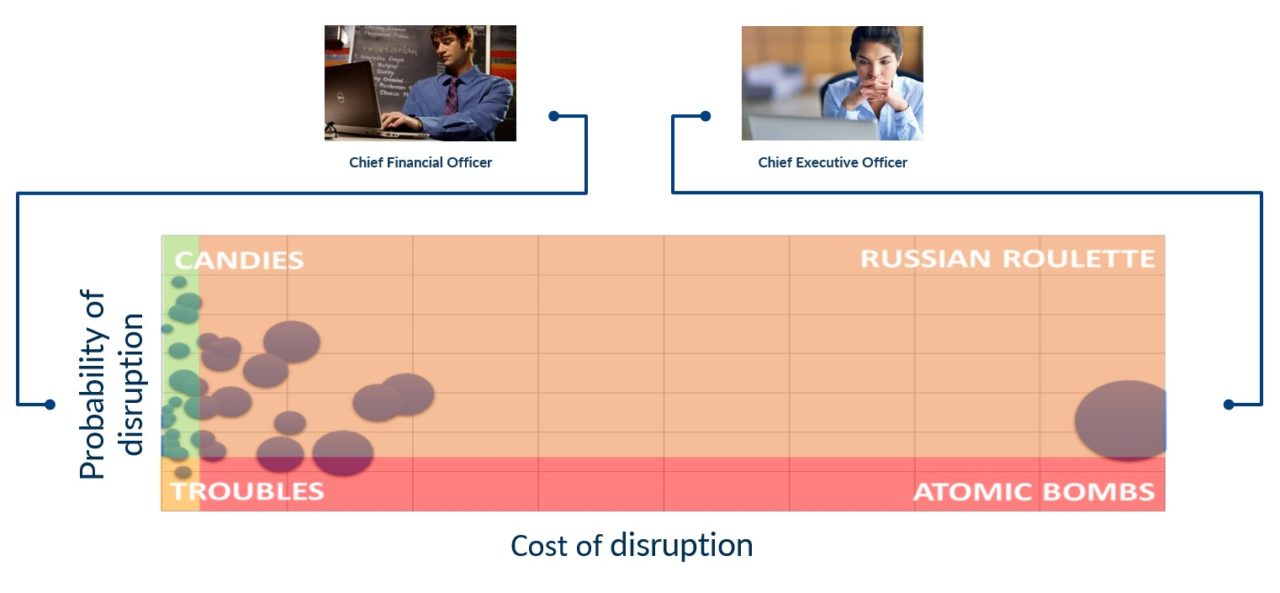
Supponiamo che esista una app, disponibile per questo, che sia scaricabile da tutti i manager potenzialmente toccati dagli impatti di questa relazione, come il direttore finanziario o l’amministratore delegato. Attraverso questa app, essi vogliono mappare (per il nuovo fornitore e per tutti i fornitori rilevanti) la situazione di rischio ovvero (come ci insegna la teoria) la probabilità che il fornitore generi un evento avverso e la magnitudo delle conseguenze di questo evento. Al fine di valutare anche l’opportunità economica persa che si avrebbe rinunciando a tale fornitura, l’app dovrebbe anche mappare il valore economico che si potrebbe generare accettando di lavorare con quel fornitore (in Figura 6 rappresentato dalla dimensiona della sfera).
Come si potrebbe costruire una tale applicazione?
Riprendendo l’esempio architetturale già visto per lo smartphone, alcuni dei dati rilevanti per questa applicazione provengono da risorse IT che sono già a disposizione dell’impresa (sistemi Legacy) come ad esempio l’ERP (categorie merceologiche acquistate, spending totale su quel fornitore), il PLM (distinte basi, e dunque in quali prodotti finiti sono impiegati i componenti forniti) ed il CRM (budget di vendita di quei prodotti, e le marginalità attese). Altri dati utili per l’applicazione potrebbero provenire dai sistemi di fabbrica, ad esempio registrando anomalie segnalate dagli impianti durante il processamento dei materiali forniti: un declino nella qualità nei materiali forniti può essere un segnale debole, precursore di possibili problemi più seri di controllo di processo, oppure di difficoltà finanziarie che possano affliggere una impresa fornitrice. Infine attraverso risorse cloud o database online è possibile acquisire informazioni relative alla solidità finanziaria di un’impresa, a problematiche legali, e anche collegarsi a piattaforme di eSourcing per valutare l’esistenza di forniture alternative, e con che tempi.
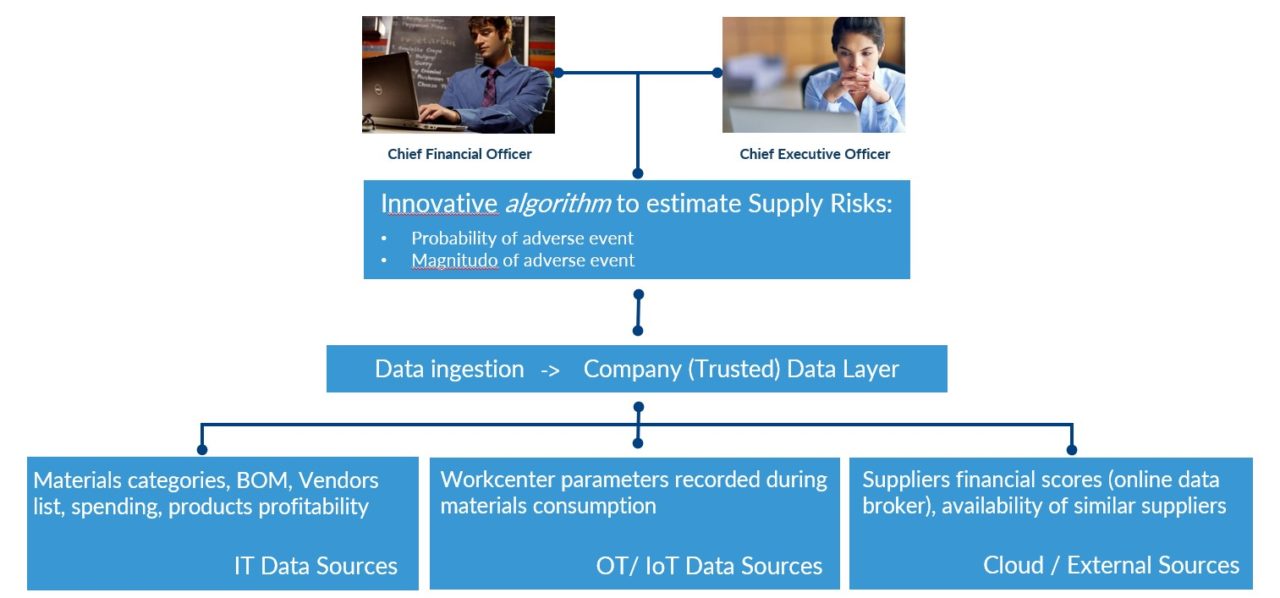
Componendo tutte le fonti dati, un algoritmo appositamente progettato potrebbe stimare la probabilità di un evento avverso (fallimento finanziario, dispute legali, perdita di controllo sul processo), calcolare con precisione le conseguenze economiche di questo evento (impiego del componente, ricadute sul budget di vendita e di cassa, persistenza della condizione di difficoltà prima di trovare una fornitura alternativa). Il risultato di questa elaborazione sarebbe esattamente l’informazione racchiusa nella mappa di rischio prima presentata, che periodicamente può essere consultata dai manager interessati, oppure essere diffusa in push a fronte di regole di alerting ben definite. La stessa applicazione aiuterebbe anche a definire le politiche di onboarding, aiutando a confrontare i particolari benefici economici di una relazione di fornitura rispetto al rischio di discontinuità, se definito accettabile[1].
Un’architettura di sistema informativo, a prova di futuro
Generalizzando l’esempio sopra presentato, e perfezionando il parallelo prima visto con la smartphone, possiamo dunque sbilanciarci e tratteggiare quale sarà l’architettura del sistema informativo del futuro, che trovate illustrato in Figura 8.
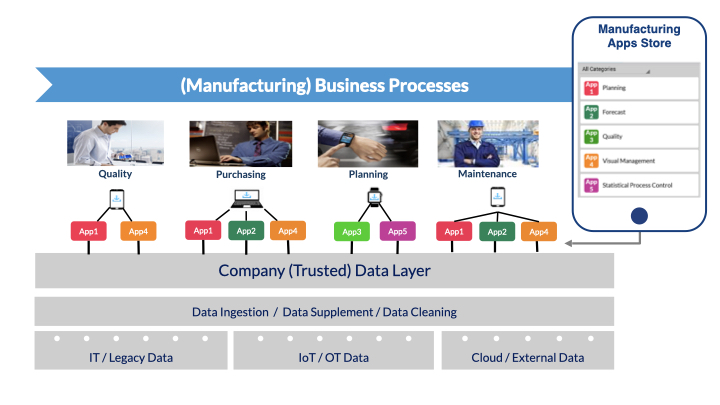
Questa immagine presenta numerosi elementi degni di commento. In primo luogo, essa generalizza l’esempio prima illustrato, facendoci immaginare il percorso di composizione che parte da diverse fonti dati (IT e sistemi Legacy, sensori e device IoT, risorse cloud e online) fino all’ecosistema di applicazioni che supporta i diversi processi di business, mettendo al centro quello che definiremo come Company Trusted Data Layer. In Figura 8 si menzionano inoltre tutti gli elementi della catena del valore del dato, come le attività di ingestione, integrazione e pulizia dei dati, e si fa implicito richiamo alle tre sfide prima illustrate (sfida tecnologica legata all’IoT e più in ampio alla quarta rivoluzione industriale, focalizzazione sulle incombenze manageriali più complesse e destrutturate[2], vicinanza al modello esperienziale e cognitivo dei giovani talenti).
Il Company Trusted Data Layer al centro della nuova architettura dei sistemi informativi
L’elemento centrale della nuova architettura è rappresentato da quello che denomineremo, nel resto di questa collana di White Papers, come Company Trusted Data Layer: esso è uno strato in cui (grazie a tecnologie di connessione, virtualizzazione ed integrazione, che saranno meglio descritte nel White Paper 2) si ritrovato tutti i dati dell’impresa, verificati e resi affidabili per il successivo utilizzo nei processi aziendali, e pronti ad essere trasformati in informazioni utili ai manager tramite gli algoritmi ospitati nello strato applicativo soprastante. Un altro aspetto distintivo del Trusted Data Layer (TDL) sono le tecnologie, ma soprattutto gli standard di descrizione e condivisione dei dati, che lo rendono una piattaforma universale su cui utenti, consulenti o altri sviluppatori possono fare riferimento per arricchire le applicazioni già disponibili. A queste, ovvero al catalogo delle applicazioni disponibili e collegate al TDL, sarà dedicato il White Paper 3.
Conclusioni: verso il Digital Lake, il nuovo sistema informativo aziendale costituito da un ecosistema di business apps
In questo primo White Paper è stato tracciato il percorso che porta della vecchie architetture di sistema informativo ad una nuova visione architetturale in grado di cogliere le tre grandi sfide che aspettano le aziende nei prossimi anni. Questo disegno ha speciale valenza per le realtà manifatturiere e, in generale, per il mondo delle operations (logistica, porti e aeroporti, centri di analisi medica, magazzini ospedalieri, etc.) ma in realtà si applica uniformemente a tutte le imprese, purché si generalizzi la fonte dati rappresentata dal blocco delle OT (Operational Tecnologies) / Industrial IoT con il più ampio insieme dell’IoT (dati da sensori posti realtà fisica, dati da prodotti connessi).
Attraverso esempi e schemi abbiamo voluto porre in evidenza come, mentre in passato esisteva una prevalenza per l’approccio best of breed, così crediamo che nel futuro si amplierà ulteriormente la pletora dei programmi (App) che supporteranno i diversi processi decisionali: immaginate quanti problemi manageriali specifici (oltre all’esempio discusso relativo alla valutazione del rischio di fornitura) andrebbero indirizzati da altrettante App che lavorano integrando dati da sistemi IT interni, dal mondo fisico e dal cloud: risposta a RFQ, stime del costo di produzione a regime, definizione del budget dei costi della non qualità, definizione del pricing di un servizio, definizione della combinazione dei servizi più probabile che un cliente possa acquistare, proposta di pricing promozionale per acquisto ricambi in fine vita, etc.
Di fronte a questa frammentazione del quadro applicativo, si manterrà, anzi crescerà di importanza, l’enfasi sull’integrazione del dato, il quale si accentrerà non solo logicamente ma anche tecnologicamente in un “luogo” rappresentato dal Trusted Data Layer da cui, attraverso opportuni standard di rappresentazione e regole di esposizione, il dato che serve verrà reso disponibile verso l’applicazione corretta.
Questa architettura è il riferimento alla base di Digital Lake, il nuovo sistema informativo aziendale costituito da un ecosistema di business apps pensate per affiancarsi al lavoro di manager e dipendenti, appoggiate ad un’unica piattaforma di raccolta, verifica e accesso ai dati aziendali, da qualsiasi fonte essi provengano. Alla tecnologia di Digital Lake, all’ecosistema di applicazioni e ad alcuni casi di adozione saranno dedicati i prossimi White paper di questa collana.
Scopri come riorganizzare i sistemi informativi, visitando il sito Digital Lake
Questo articolo è frutto di una collaborazione dei due autori; Giovanni Miragliotta ha curato maggiormente i contenuti di scenario e di inquadramento concettuale, mentre Marco Tessarin ha curato maggiormente i contenuti applicativi.
[1] L’applicazione qui descritta esiste già, www.rischiodifornitura.it, e sarà presentata nel WP #3, dedicato al catalogo applicativo.
[2] Essendo tutte le altre incombenze manageriali già coperte dalla maturità dei sistemi transazionali esistenti.
Il percorso di approfondimento prosegue con il servizio Tecnologie open e modelli dati comuni nei sistemi informativi manifatturieri del futuro






