
Indice degli argomenti
Master data di produzione: perché affrontare questo tema?
I dati di base o master data di produzione sono informazioni elementari e formalizzate, che descrivono le attività, l’organizzazione e gli asset tangibili e intangibili di ogni azienda manifatturiera. Essi sono fondamentali per la realizzazione di pressoché tutte le attività del processo primario e di molti processi di supporto (Porter 1985). La loro configurazione e il loro aggiornamento coinvolgono più attori in momenti temporali diversi: lo sviluppo di un nuovo prodotto, il rinnovo del parco macchine, oppure l’acquisizione di un nuovo cliente (Secchi, 2000).
Non venendone compresi appieno né l’utilità né l’impatto, la gestione dei master data è spesso delegata a livelli di responsabilità che mancano dell’ampiezza di visione necessaria. La loro configurazione è di solito lasciata all’improvvisazione dei singoli, senza un disegno complessivo e coerente, e il loro aggiornamento è spesso realizzato più per la diligenza dei responsabili che per la presenza di ben precise procedure, responsabilità, tempistiche, verifiche e sistemi di incentivazione. Così, non di rado si arriva a stratificazioni quasi inestricabili, con grave rischio, perché dati deboli rendono deboli anche i processi che vi si appoggiano.
Il punto di vista illustrato da quest’articolo è quindi che i vertici aziendali dovrebbero occuparsi con maggiore costanza e convinzione dell’impostazione ed aggiornamento dei dati di base, e l’obiettivo che viene in queste pagine perseguito è, coerentemente, di fornire le evidenze su cui poggia tale affermazione.
A tale scopo, il capitolo seguente descrive i principali dati di base di un’azienda manifatturiera; il capitolo successivo fa il punto sui loro utilizzi in azienda, ed evidenzia le problematiche determinate da dati di base incompleti, scorretti o non aggiornati. Successivamente vengono presentati i principali criteri di gestione dei dati di base, con particolare riferimento alle attività di configurazione ed aggiornamento. Infine, l’ultimo capitolo presenta una serie di spunti conclusivi.
Master data di produzione: che cosa sono e perché sono sempre più importanti
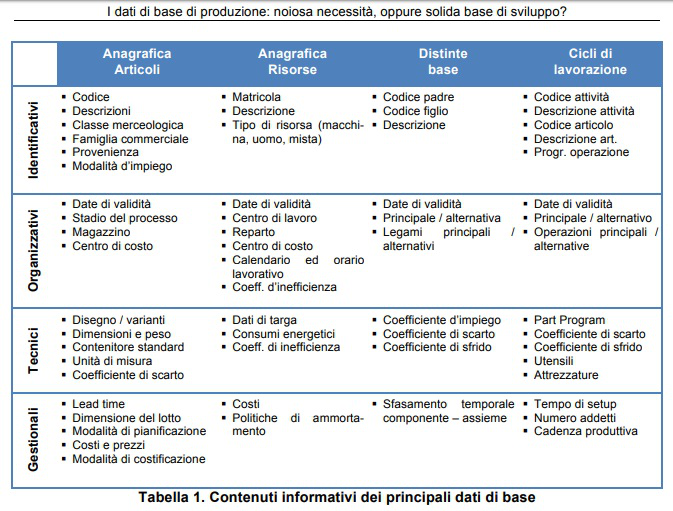
Dal punto di vista informativo, i dati di base sono un assieme di entità e relazioni (Chen, 1976): le entità modellano degli “oggetti di business” indipendenti (ad esempio, l’anagrafica articoli), mentre le relazioni fanno riferimento ai legami fisici o logici tra due o più entità: ad esempio, un legame di distinta base descrive la relazione tra un articolo padre ed un figlio.
Soffermandosi sui soli oggetti di business più rilevanti, la tabella 1 illustra i loro principali contenuti informativi, raggruppandoli nelle principali aree d’utilizzo:
- dati identificativi, che descrivono e catalogano i business objects cui si riferiscono
- dati organizzativi, che specificano come i business objects di riferimento si inseriscono all’interno del modello organizzativo aziendale
- dati tecnici, che indicano le principali caratteristiche tecnologiche dei business objects a cui si riferiscono, e
- dati gestionali, che supportano le decisioni all’interno dei principali processi decisionali ad essi riconducibili.
Master data di produzione: a cosa servono
Con l’obiettivo di esplicitare la rilevanza e l’impatto aziendale dei dati di base, nei paragrafi successivi si effettua una carrellata degli impatti ed utilizzi dei dati di base nei principali processi sia interni, sia collaborativi con i fornitori oppure con i clienti (Perona e Saccani, 2004b; Saccani e Perona, 2007; Berson e Dubov, 2007).
Master data di produzione nel processo primario
I dati di base identificano e descrivono i principali asset fisici che prendono parte al processo primario, quali: il sistema produttivo; il sistema distributivo; la gamma di prodotti, sottogruppi ed articoli d’acquisto; il sistema organizzativo; la rete di fornitura, etc.
Attraverso l’impiego centralizzato dei dati di base è quindi possibile “parlare la stessa lingua” tra funzioni ed organizzazioni diverse. Attraverso buoni dati di base è possibile anche tracciare i flussi di materiali che attraversano l’azienda, pilotati dai principali processi manifatturieri e logistici. Ad esempio, la disponibilità di un buon sistema di codifica dei materiali, unitamente ad un sistema MES (Manufacturing Execution System), consente di identificare le singole unità di materiale presenti in azienda, e di tracciarne l’ubicazione fisica, dall’ingresso materiali alla spedizione a cliente (Helo et al., 2014).
Accanto alla tracciabilità, che dà un contenuto prevalentemente passivo, i dati di base possono anche fungere da guida attiva per pilotare i flussi di materiali, attrezzature ed utensili e le sequenze di lavorazione, considerando i vincoli di precedenza, fattibilità tecnica ed interferenza.
Quanto è vero per i flussi fisici, può esserlo anche per tracciare i flussi d’informazioni, documentali e decisionali: ad esempio, tramite un buon sistema di process management si può ottenere che ciascun documento (es: un’ordine, una bolla di lavorazione, o una richiesta d’acquisto), appena generato, sia dispacciato verso chi lo deve processare e soddisfare: questo non è utile solo per dematerializzare i processi (Perego et. al. 2010), ma anche per controllare chi ha fatto quale attività quando.
Quindi, i dati di base sono evidentemente utili per identificare e controllare i job, ossia le unità di lavoro (manifatturiero o informativo-decisionale) che circolano nel sistema. Lo stesso si può anche dire per le unità “shop oriented”, ossia le risorse (fisiche o organizzative) che fungono da server nei processi fisici e decisionali. Ad esempio, attraverso una buona modellazione delle risorse del sistema e delle loro interdipendenze si può facilitare la rilevazione ed il monitoraggio del loro stato operativo (Grando e Turco, 2005).
L’identificazione ed il tracciamento dei flussi fisici ed informativi non ha un’utilità solo immediata: infatti, un’adeguata memorizzazione e storicizzazione delle informazioni raccolte consente a posteriori di attuare la rintracciabilità di queste entità. Ad esempio, una volta riscontrata la presenza di un difetto grave su un lotto di componenti d’acquisto, sarà possibile risalire a tutti i prodotti finiti che hanno montato i componenti di tale lotto ed attuare un richiamo mirato e circoscritto (Stefansson e Tilanus, 2002).
Inoltre, l’elaborazione statistica a posteriori dei dati raccolti, segmentati attraverso criteri opportuni, può permettere ai manager di identificare, affrontare e risolvere i problemi nascosti del sistema manifatturiero (Lee et. al., 2013). Questo ruolo è facilitato dalle funzionalità di pegging multilivello (Müller et. al., 2008) che molti sistemi informativi aziendali consentono di attivare e che, ad esempio, permette di partire da un ordine cliente, risalire a tutti i codici prodotto finito presenti in quell’ordine, esploderne i sottogruppi ed i componenti, esplorare i relativi ordini di produzione e di acquisto, ed in ultima analisi risalire ai fornitori o ai reparti ed agli operatori che hanno svolto le diverse attività produttive.
Per quanto concerne il ciclo attivo, anagrafiche e distinte base opportunamente progettate possono abilitare i configuratori di prodotto (Forza, Salvador, 2002), applicativi capaci di supportare la configurazione interattiva di prodotti complessi, tenendo conto di tutte le opzioni offerte e di tutti i vincoli tecnici o commerciali di infattibilità. È inoltre possibile offrire ai clienti servizi logistici avanzati, quali VMI (vedasi per esempio: Kaipia et. al. 2002), e consignment stock (Valentini e Zavanella, 2003).
Dati di base di produzione e controllo di gestione
I dati di base assolvono alla importantissima funzione aziendale del controllo dell’efficienza ed efficacia dei processi. Senza dati di base completi, corretti e tempestivi è infatti impossibile una corretta valorizzazione sia a preventivo sia a consuntivo delle principali prestazioni operative ed economiche di un sistema aziendale. Secondo molti studiosi (Cagliano e Spina, 2000), le prestazioni aziendali, possono essere classificate nelle aree dei tempi, dei costi e della qualità, e ciascuna di queste tre categorie di prestazioni richiama una ben precisa funzione dei dati di base.
Anzitutto, sotto il profilo dei tempi, i dati di base forniscono informazioni di riferimento, atte a supportare la tempificazione dei processi manifatturieri e di fornitura a preventivo, ed a verificarne successivamente la puntualità a consuntivo. Il lead time indica la durata (prevista o effettiva) di un’attività (Bartezzaghi e Spina, 1994). Tale informazione è frequentemente codificata all’interno dell’anagrafica articoli sia per quanto attiene gli articoli acquistati all’esterno (per i quali indica pertanto lead time di fornitura) sia per gli articoli interni (rappresentando così il lead time di produzione). Ricomponendo i lead time dei vari articoli coinvolti lungo un ramo di distinta base, è possibile comporre la distinta base tempificata, attraverso la quale può essere modellato il lead time dell’intero processo.
Il secondo elemento menzionato, fa riferimento ai costi dei prodotti, dei flussi e delle attività. Per poter calcolare i costi a preventivo, è essenziale conoscere i materiali consumati (codificati nei legami di distinta, attraverso i coefficienti di impiego), e l’effort delle risorse umane (lavoro) e tecniche (macchine ed attrezzature). Le informazioni di questo tipo sono racchiuse nelle operazioni di ciclo, ed esprimono l’impegno dei macchinari e/o del personale richiesto per la produzione di un’unità di output dello specifico articolo di riferimento. Il corretto calcolo dei valori fa in particolare riferimento a due fonti principali di informazioni (Son et al., 2011):
a). la quantità della risorsa consumata o utilizzata, reperibile sui legami di distinta base (materiali d’acquisto) oppure sulle operazioni di ciclo (impegno macchina; impegno uomo)
b). il costo unitario delle singole risorse, reperibile tipicamente all’interno dei vari fondi contabili: ad esempio il libro cespiti per i macchinari; l’anagrafica articoli per gli articoli d’acquisto esterno; il libro paga per i costi del personale, etc.
La terza funzione dei dati di base riconducibile all’area del controllo fa riferimento alla qualità, dal punto di vista della conformità del prodotto e del processo. E’ solo avendo prefissato una serie di caratteristiche morfologiche e tecniche del prodotto o dei suoi articoli costituenti, ed avendole codificate all’interno di una opportuna anagrafica che si può riuscire a supportare un processo di verifica della conformità. Tale processo può essere realizzato sui materiali in ingresso; sul materiale in produzione così come sui prodotti in uscita (Ahire et al. 1996).
Master data di produzione al servizio della pianificazione
L’esempio più evidente di come i dati di base possono supportare la pianificazione è costituito dalla necessità di raggruppare per affinità gli articoli pianificati, al fine di ragionare per famiglie omogenee, anziché per singoli articoli, riducendo la complessità dimensionale del processo di pianificazione. L’affinità tra articoli può essere definita in molte maniere, ad esempio secondo un criterio merceologico, morfologico, oppure produttivo, e ciascuno di questi criteri fa riferimento a ben precise informazioni, tipicamente codificate e reperibili all’interno dell’anagrafica articoli oppure dei cicli di lavorazione (Bacchetti e Saccani, 2012, Perona et al. 2009).
Anche la tempificazione dei flussi di materiali, siano essi di acquisto, di produzione oppure di distribuzione richiede opportune informazioni anagrafiche e di struttura (Mather, 1986). A livello tattico c’è la necessità di stabilire dei piani operativi che indichino quando verrà acquistato, prodotto, stoccato, oppure consegnato cosa e dove. A livello esecutivo, poi, sarà necessario garantire che i tempi previsti in sede di pianificazione vengano, effettivamente, rispettati.
Tale funzione è assolta attraverso i diversi lead time (di acquisto, di produzione o di distribuzione) codificati nelle anagrafiche. Il valore assegnato loro è di importanza critica: infatti tempi a sistema più lunghi di quelli effettivi garantiscono il rispetto degli appuntamenti logistici, ma implicano l’accumulo d’inutili scorte di ciclo, in quanto i materiali vengono sistematicamente predisposti prima di quando effettivamente servono; viceversa, l’impiego di tempi a sistema minori di quelli effettivi, se da un lato impedisce la detenzione di scorte in eccesso, sarà invece responsabile di sistematici ritardi.
Questo problema non è di facile soluzione se la pianificazione è svolta a capacità infinita. Infatti, la pianificazione a capacità infinita richiede l’utilizzo in input dei lead time pianificati per le varie fasi operative del processo primario (Wight, 1995), mentre al tempo stesso determina in output il carico del sistema (ovverossia il livello di output pianificato per specifici periodi temporali all’interno dell’orizzonte di pianificazione), che a sua volta, in virtù della nota legge di Little (Little & Graves, 2008), determina i lead time effettivi del sistema. Pertanto, nella pianificazione a capacità infinita il lead time di una specifica attività o processo è sia input, sia output del processo medesimo.
Un altro degli aspetti qualificanti di un processo di pianificazione è la possibilità di dominare le alternative esistenti, al fine di poter offrire il maggior numero di opzioni, atte a risolvere i numerosi conflitti che insorgono nell’attribuzione delle risorse condivise. Si parla in questo caso di: fornitori alternativi di un medesimo materiale; materiali fungibili tra di loro; distinte base alternative per realizzare il medesimo prodotto finito, oppure cicli tecnologici alternativi per realizzare determinati processi manifatturieri Czerwinski et al.1994).
Dominare le alternative logistico-produttive nel senso sopra definito e codificarle all’interno dei dati di base mette a disposizione una risorsa in più per garantire la robustezza dell’output del processo primario rispetto alle sua tipiche perturbazioni, quali i ritardi di fornitura, le non conformità, i guasti dei macchinari, oppure le oscillazioni della domanda. Quindi, la disponibilità di alternative consente di mantenere il più possibile stabile il tempo di risposta all’ordine, il costo di produzione e la qualità del prodotto al variare delle condizioni endogene ed esogene (Nonaka et al., 2013).
Un’altra caratteristica utile dei dati di base per il processo di pianificazione è la loro capacità di modellare i più significativi vincoli del processo produttivo: ad esempio quali materiali possono essere lavorati da quali macchinari; l’ordine con il quale possono essere svolte le operazioni produttive; oppure le durate minime di specifiche lavorazioni. Tutte queste informazioni sono fondamentali per sviluppare in automatico dei piani operativi realistici a capacità finita (Carvalho et al., 2014).
E tra le funzioni dei dati di base utili per il processo di pianificazione certamente è indispensabile citare anche la focalizzazione verso gli aspetti più critici. Per la nota legge di Pareto (Hardy, 2010), solo un numero limitato di ordini, articoli, risorse o attività sono quelli che, effettivamente, determinano le prestazioni del processo primario, mentre la maggioranza di queste entità ha normalmente un impatto molto basso, se non addirittura nullo: ed è per l’appunto compito del sistema di pianificazione di evitare un eccessivo livello di dettaglio, focalizzando l’attenzione dei pianificatori sui pochi aspetti chiave.
Come i dati di base di produzione supportano lo sviluppo di un nuovo prodotto
Il processo di sviluppo e manutenzione dei prodotti è una delle principali sorgenti dei dati di base: si potrebbe addirittura asserire che una delle principali funzioni complessivamente svolte dai dati di base sia quella di codificare in modo formalizzato il know-how tecnico di un’azienda manifatturiera, in maniera da renderlo disponibile e trasmetterlo alle varie fasi del processo primario o ai processi di supporto.
I dati di base, se opportunamente progettati, possono servire per indirizzare il processo di progettazione verso atteggiamenti virtuosi con riferimento alle altre fasi di generazione del valore (Miragliotta et al., 2002), attraverso leve quali la modularità della gamma di prodotti (Brun & Zorzini, 2009; Tersine, 1994), la standardizzazione della componentistica (Wacker & Treleven, 1986), il riutilizzo e la comunanza di componenti e materie prime. A loro volta, tali logiche abilitano forme di codesign con i fornitori nello sviluppo dei diversi moduli funzionali (Spina et al., 2001 a e b).
Uno dei compiti principali affidati ai dati di base all’interno del processo di sviluppo del nuovo prodotto è relativo alla gestione delle varianti di gamma sia nello spazio (modelli, versioni, etc.) sia nel tempo (restyling, miglioramento del prodotto). La gestione delle varianti disponibili in uno specifico istante di tempo può essere effettuata o attraverso la loro gestione nei record di struttura delle distinte base (Brandolese et al., 1991), oppure organizzando la distinta per varianti mediante un approccio “Add and Delete” (Van Veen & Wortmann, 1992; Romanowski e Rakesh Nagi, 2004).
La gestione delle varianti di prodotto nel tempo invece pilota le tempistiche di phase-out degli articoli obsoleti e di corrispondente phase-in dei corrispondenti codici nuovi attraverso l’indicazione delle date di inizio e fine validità di ciascun business object. C’è poi l’esigenza, soprattutto nel settore dei beni strumentali, di tenere traccia delle configurazioni del prodotto venduto a specifici clienti (Kashkoush e H. ElMaraghy, 2014): questa è una funzione tipicamente abilitata dai sistemi PLM (Product Lifecycle Management) attraverso una opportuna codifica delle configurazioni del prodotto (Terzi et al. 2010).
Master data management: la rilevanza di una accurata gestione
Il know-how di un’azienda è un asset intangibile, che viene generato, modificato e migliorato attraverso il lavoro continuo di manager, tecnici, progettisti e capireparto. I dati di base costituiscono uno dei modi attraverso cui questo fondamentale patrimonio viene reso esplicito e quindi può essere appropriato dall’azienda. È una generale conclusione di molti lavori di ricerca svolti in questi ultimi anni, e ben sintetizzata dal rapporto Gartner n° G00136958 (White et al., 2006) che una corretta impostazione ed utilizzo dei dati di base abbia a che fare con la strategia aziendale, l’organizzazione dei processi e la qualità delle informazioni a supporto delle decisioni più che con la tecnologia di prodotto o di processo.
Va inoltre considerato che i medesimi dati possono venire impiegati in processi diversi, e che un medesimo processo può impiegare informazioni con diverse provenienze. Questo rilievo, apparentemente banale, evidenzia come una cattiva progettazione e manutenzione dei dati di base abbia un elevato potenziale di peggiorare l’efficienza e l’efficacia complessive di un’organizzazione. Così ad esempio, un tempo ciclo sbagliato impatta negativamente: sulla programmazione della produzione, sulla valorizzazione dei costi del prodotto e sul calcolo dell’efficienza produttiva; ed allo stesso modo, un legame di distinta errato provoca acquisti inesatti, obsoleti a magazzino, il prelievo di materiali inutili, ritardi nelle operazioni di montaggio e quindi potenzialmente anche nelle consegne, oltre ad un calcolo costi errato.
L’attenzione verso una corretta gestione della complessità dell’azienda e della catena del valore entro cui si opera rappresenta una leva potente per rafforzarne la capacità di generare fatturato e profitti (Miragliotta et al. 2002; Perona & Miragliotta, 2004). Per tenere sotto controllo la complessità occorre, identificare e calcolare opportuni indicatori numerici che permettano di quantificarne le 3 dimensioni: varietà, relazioni e dinamicità. Ed una corretta impostazione ed ancora di più una efficace e tempestiva manutenzione dei dati di base sono ingredienti chiave per tenere sotto controllo l’entropia generata all’interno dei processi aziendali, e quindi la crescita della complessità del sistema aziendale, ed in ultima analisi quindi la capacità dell’azienda di generare valore sostenibile nel tempo.
Le scelte di impostazione dei dati di base di produzione
L’aspetto fondamentale che occorre considerare nel progetto dei dati di base è il corretto livello di dettaglio da impiegare per la modellazione dei processi. Non è, infatti, strettamente necessario tracciare tutti i codici intermedi, le operazioni produttive anche più minute, i macchinari meno significativi: anzi, tralasciare gli elementi non critici è utile in quanto riduce le attività di data entry e semplifica la gestione del sistema, concentrando l’attenzione su quegli oggetti che possono avere un impatto significativo sul business.
Nel costruire il disegno complessivo dei dati di base, è inoltre necessario tenere conto delle diverse necessità dei processi supportati, che derivano dal diverso modo attraverso cui ciascuno di loro si sviluppa, ed utilizza le informazioni contenute nei dati di base.
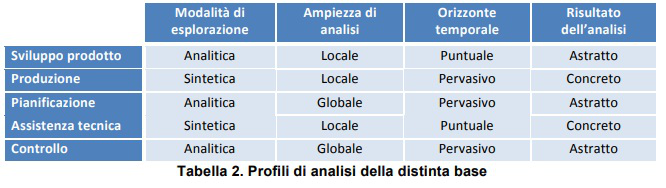
Ad esempio, non sempre esiste una perfetta identità tra dati di progettazione e di produzione, perchè il processo di progettazione è di tipo analitico, partendo dal complessivo e sviluppandosi sempre più verso il particolare, ed è astratto, interessandosi di funzioni logiche: così, è piuttosto ovvio che la distinta di progettazione venga sviluppata partendo dal prodotto finito, e scomponendolo via via nei sottogruppi, gruppi e particolari che conferiscono al prodotto le caratteristiche desiderate. Se ora guardiamo al medesimo prodotto con gli occhi della produzione, abbiamo la necessità di procedere con direzione sintetica (ossia, partendo dai singoli componenti, ed aggregandoli sempre più fino al prodotto finito) e per di più lavorando sempre con oggetti fisici (quindi in una dimensione concreta). Pertanto, uno specifico aggregato funzionale presente nella distinta base di progettazione potrebbe anche non avere una concreta esistenza nella produzione, perché ad esempio risulta impossibile montarlo, oppure perché non ha una natura fisica unitaria, ma è invece composto da più parti fisicamente separate (Brandolese at al., 1991).
Analoghe esigenze di distinzione delle funzioni si manifestano a supporto delle attività dell’assistenza post vendita (Saccani et al. 2007). Tale fase ha la necessità di essere supportata da veri e propri cicli di disassemblaggio, che devono tenere conto della limitata dotazione di attrezzature talvolta disponibili nelle attività realizzate in field, così come dalla definizione in anagrafica delle parti di ricambio (o addirittura di interi kit di ricambi).
A puro titolo di esempio la tabella 2. riassume i profili di analisi della distinta base (Garwood, 2000).
Appare inoltre chiara l’esigenza di configurare i dati di base in maniera che essi, in termini generali, facilitino il sistema transazionale nel mantenersi aggiornato rispetto alla situazione reale (Dreibelbis et al. 2008). Questo fondamentale obiettivo viene raggiunto attraverso una progettazione che punti a sviluppare i dati di base in maniera completa e corretta, oltre ad aggiornarli in modo tempestivo. La completezza corrisponde alla capacità di considerare tutti gli aspetti rilevanti del sistema fisico modellato; la correttezza è invece stabilita quando vi è una sostanziale corrispondenza con il sistema fisico modellato; infine, la codifica e l’aggiornamento dei dati di base avviene in termini sufficientemente tempestivi, quando garantisce il loro rapido adeguamento rispetto ai cambiamenti di scenario.
Fa parte integrante dell’impostazione dei dati di base il disegno logico della struttura dati atta a contenerli: ad esempio, il modello entità-relazioni, le tabelle con le loro chiavi ed i collegamenti relazionali, e gli attributi da inserire in ciascuna tabella (Talheim 2013). E’ in questa fase che occorre assicurarsi che tutti i processi a valle possano trovare all’interno della struttura dei dati di base tutte le informazioni necessarie, ed al tempo stesso che tutti i dati inseriti abbiamo un effettivo utilizzo in almeno uno dei processi a valle.
La definizione dell’architettura dei dati di base comprende anche: la scelta di modularizzare la gamma dei prodotti, poiché la conseguente riconfigurazione delle distinte base e dell’anagrafica articoli accresce la facilità e rapidità con cui si possono inserire a sistema le distinte dei nuovi articoli (Magnusson & Pasche, 2014); e la scelta di un sistema di codifica parlante, che facilita lo sfruttamento delle comunanze della componentistica, rendendo più naturale la ricerca di articoli già in anagrafica che corrispondono a ben determinate caratteristiche.
Ultima in ordine di citazione, ma non d’importanza, vi è la scelta della piattaforma applicativa da utilizzarsi per la codifica, l’utilizzo e la modifica dei dati di base, ivi comprendendo il data base, le procedure e l’interfaccia utente. Tale applicativo andrà integrato ovviamente con gli altri applicativi del sistema informativo che impiegano i dati di base e dovrà ottemperare alle ovvie esigenze di sicurezza attiva (safety) e passiva (security) dei dati (Rgnier-Pcastaing et al. 2013).
Il ciclo di vita dei Master data di produzione
Anche i dati di base, pur essendo intrinsecamente statici, sono caratterizzati da un ciclo di vita (Hubert Ofner et al. 2013), che prevede quattro fasi principali.
1). La generazione del dato: durante la quale è importante assicurare la standardizzazione dei dati al fine di evitare doppioni che possono portare alla generazione di errori, e garantirne l’integrità referenziale al fine di evitare disallineamenti.
2). L’utilizzo, durante il quale è di basilare importanza permettere agli utenti di discriminare con facilità i dati principali rispetto a quelli alternativi (ad esempio, nei cicli di lavorazione) ed i dati attivi rispetto a quelli non ancora entrati in vigore, oppure già scaduti.
3). L’aggiornamento, che è realizzato tramite la gestione delle versioni, l’immissione di nuove informazioni e la correzione dei dati scorretti o obsoleti. È fondamentale in questa fase disporre di procedure chiare ed efficaci che permettano a chiunque identifichi un errore entro un dato di base, di segnalarlo e documentarlo opportunamente al responsabile dell’aggiornamento, che a sua volta provvederà alla correzione.
4). L’obsolescenza del dato, che cessa di essere in vigore e viene quindi sostituito da un’altra versione più aggiornata. Questa fase va opportunamente pianificata e resa nota con anticipo, per consentire a tutte le parti coinvolte di prendere le contromisure rese necessarie dalla modifica apportata.
Master data: le responsabilitá e le procedure
Come si è già anticipato, la formalizzazione del know-how tecnico realizzata attraverso i dati di base, costituisce il presupposto affinché sia l’azienda ad esplicitarli e ad appropriarsene, anziché lasciare che questa conoscenza resti implicita e sia quindi patrimonio di poche persone, che potrebbero sfruttarla a proprio vantaggio. Da qui quindi la necessità di provvedere alla loro manutenzione nel tempo, ossia al progressivo popolamento della base dati, ed all’aggiornamento dei dati ivi contenuti per adeguarli all’evoluzione della realtà fisica (Vilminko-Heikkinen & Pekkola, 2013).
Dovendo coinvolgere e coordinare diversi enti aziendali, il processo di creazione e aggiornamento dei dati presenta rischi relativi a: tempi lunghi, disallineamento dei dati o incongruenze negli stessi (Loshin, 2010). Pertanto necessita di una chiara definizione delle attività da svolgere, delle corrispondenti responsabilità, delle procedure e metodologie da seguire, dei tempi entro cui ciò deve avvenire e degli indicatori che possano consentire di controllarne l’efficienza e l’efficacia.
Gli obiettivi da porsi sono di rendere il processo rapido e a prova di errore: non è infrequente che proprio per questo le aziende manifatturiere centralizzino tale responsabilità su dati di base o master data, affidandola all’Ufficio Tecnico. Questa scelta è però criticabile perchè non tutti i dati di base vengono generati all’interno dell’Ufficio Tecnico, ed anche circoscrivendo la nostra analisi ai soli dati di base che, effettivamente, nascono qui, molti dei loro attributi devono essere inseriti ed aggiornati da altri Enti aziendali: ad esempio, i tempi ciclo sono di pertinenza della Produzione; i coefficienti di scarto della Qualità; eccetera.
Una corretta e ordinata gestione dei master data quindi è sì favorita dall’istituzione di una regia centrale, ma richiede anche una ampia delega sulla responsabilità dell’inserimento / aggiornamento delle informazioni, che non va attribuita per tabella ma per attributo, in relazione agli specifici processi all’interno dei quali ciascun attributo viene definito o utilizzato. Alla regia centrale spetta la responsabilità di supervisione e assicurazione che i dati, nel loro complesso, vengano tempestivamente inseriti, aggiornati e corretti. Essa viene pertanto facilitata nello svolgimento di questo compito da procedure automatiche che, in modalità batch, scandagliano i database aziendali alla ricerca di informazioni mancanti, incongruenti o scorrette. In tale ambito, ciascun Ente deve essere responsabile dell’inserimento puntuale e della corretta manutenzione dei dati di propria competenza.
Lo svantaggio di tale modello è che può anche implicare procedure di inserimento ed aggiornamento composte di molte fasi successive: ad esempio, i cicli di lavorazione possono essere inizializzati dall’Ingegneria di processo; successivamente: la Qualità può indicare i corretti coefficienti di scarto; la Produzione può sviluppare fasi alternative ed eventualmente aggiornare i tempi ciclo o le efficienze; etc. Per mantenere in fase questi aggiornamenti e completamenti successivi, può essere utile giovarsi di un applicativo di workflow management che, se ben configurato, può aggiornare tutti gli utenti interessati quando uno specifico dato è stato correttamente aggiornato dall’Ente preposto, oltre che mettere a disposizione dei diversi utenti un meccanismo facile per la segnalazione di eventuali errori da correggere.
Conclusioni
Questo articolo illustra molte modalità attraverso le quali dei dati di base ben configurati ed efficacemente aggiornati possono contribuire alla creazione di un solido valore d’impresa, sia rendendo più efficaci ed efficienti i processi, sia tramite la possibilità di consolidare ed appropriare la conoscenza implicita dell’azienda.
Il ruolo dei master data quindi non è, come spesso troppo semplicisticamente si pensa, esclusivamente legato alle attività operative, ed analogamente essi non trovano applicazione solo nel mondo tecnico-produttivo: al contrario, essi hanno un impatto estremamente pervasivo, e per questo motivo una rilevanza strategica. Purtroppo, a dispetto di ciò, spesso le aziende attribuiscono in maniera eccessivamente circoscritta la responsabilità di configurare ed aggiornare i dati di base, ottenendo un risultato inefficace ed incongruente con le esigenze, generando gravi danni.
La diretta conseguenza di dati di base non completi, corretti o tempestivi è l’impossibilità di realizzare determinate attività di supporto decisionale o di controllo, oppure l’inaffidabilità delle informazioni ricavate attraverso le medesime. Ma ciò a sua volta fa perdere delle rilevanti opportunità in termini di efficacia ed efficienza, riducendo quindi la competitività dell’azienda.
È per questo che viene in questa sede ribadita con forza la necessità di dare alla configurazione e all’aggiornamento dei master data la rilevanza organizzativa che tali attività richiedono, affidandole a figure aziendali dotate di maggiore visione complessiva e presidiandole maggiormente da parte dei vertici aziendali.
Bibliografia
Ahire S. L., Damodar Y. G., Waller M. A., 1996. “Development and validation of TQM implementation constructs”, Decision sciences, 27 (1), pp. 23-56.
Bacchetti A., Saccani N., 2012. “Spare parts classification and demand forecasting for stock control: investigating the gap between research and practice”, Omega, 4 (6), pp. 722-737.
Bartezzaghi E., Spina G.L., Verganti R., 1994. “Lead-time models of business processes”, International Journal of Operations & Production Management, 14 (5), pp. 5-20.
Berson A., Dubov L., 2007. Master Data management and customer data integration for a global Enterprise, Mc Graw Hill Inc.
Brandolese A., Pozzetti A., Sianesi A., 1991. Gestione della produzione industriale, Milano, Hoepli.
Brun A., Zorzini M., 2009. “Evaluation of product customization strategies through modularization and postponement.” International Journal of Production Economics, 120 (1), pp. 205-220.
Cagliano R., Spina G.L., 2000. Pratiche gestionali e successo competitivo nella piccola impresa e nell’artigianato. Una Ricerca nelle Imprese Manifatturiere e nei Distretti nell’Emilia Romagna, Milano, Franco Angeli.
Carvalho A.N., Scavarda L.F., Lustosa L.J., 2014. “Implementing finite capacity production scheduling: lessons from a practical case”, International Journal of Production Research, 52 (4), pp. 1215-1230.
Chen P., 1976. “The entity-relationship model – toward a unified view of data”, ACM Transactions on Database Systems (TODS), 1(1), pp. 9-36.
Czerwinski C.S., Luh P.B., 1994. “Scheduling products with bills of materials using an improved Lagrangian relaxation technique”, Robotics and Automation, IEEE Transactions, 10 (2), pp. 99-111.
Dreibelbis A., Hechler E., Milman I., Oberhofer M., Van Run P., Wolfson D., 2008. Enterprise master data management: an SOA approach to managing core information, Pearson Education.
Forza C., Salvador F., 2002. Configurazione di prodotto, McGraw-Hill.
Garwood D., 2000. Bills of material: structured for excellence. Dogwood Publishing Company, Inc.
Grando A., Turco F., 2005. “Modelling plant capacity and productivity: conceptual framework in a single-machine case.” Production Planning and Control, 16(3), 309-322.
Hardy M. 2010. “Pareto’s law.”, The Mathematical Intelligencer, 32(3), pp. 38-43.
Helo P., Suorsa M., Hao Y., Anussornnitisarn, P., 2014. “Toward a cloud-based manufacturing execution system for distributed manufacturing”. Computers in Industry, 65(4), pp. 646-656.
Hubert Ofner M., Straub K., Otto B., Österle H., 2013. “Management of the master data lifecycle: a framework for analysis”. Journal of Enterprise Information Management, 26 (4), pp. 472-491.
Kaipia R., Holmström J., Tanskanen K., 2002. “VMI: What are you losing if you let your customer place orders?” Production Planning & Control, 13(1), pp. 17-25.
Kashkoush M., El Maraghy H., 2014. “Product Design Retrieval by Matching Bills of Materials”, Journal of Mechanical Design, 136(1).
Lee J., Lapira E., Bagheri B., Kao H. A., 2013. “Recent advances and trends in predictive manufacturing systems in big data environment”, Manufacturing Letters, 1 (1), 38-41.
Little J.D.C., Graves S.C., 2008. “Little’s law.” Building intuition, Springer US, pp. 81-100.
Loshin D., 2010. Master data management. Morgan Kaufmann.
Magnusson M., Pasche M., 2014. “A Contingency Based Approach to the Use of Product
Platforms and Modules in New Product Development”, Journal of Product Innovation Management, 31 (3), pp. 434-450.
Mather H.F. (1986). “Design, bills of materials, and forecasting: the inseparable threesome”, Production and Inventory Management Journal, 27(1), pp. 90-107.
Miragliotta G., Perona M., Portioli-Staudacher A., 2002. “Complexity Management in the Supply Chain: theoretical model and empirical investigation in the Italian household appliances industry”, in: Seuring, S., Golbach, M. (a cura di) Cost Management in Supply Chains, pp. 381-397, Physica-Verlag HD.
Müller J. Krueger J., Zeier A., 2008. “Improving global business of medium-sized enterprises by integrated processes.” in Advanced Management of Information for Globalized Enterprises, pp. 1-5, AMIGE IEEE Symposium.
Nonaka Y., Erdős G., Kis T., Kovács A., Monostori L., Nakano T., Váncza J., 2013. “Generating alternative process plans for complex parts”, in CIRP Annals of Manufacturing Technology, 62(1), pp. 453-458.
Perego A., Catti P., Marrazzi D., 2010. “Fatturazione elettronica: le priorità per la diffusione della fatturazione elettronica”, Sistemi & Impresa, 3 pp. 51.
Perona M., Miragliotta G., 2004. “Complexity Management and Supply Chain Assessment. A field study and a conceptual framework”, International Journal of Production Economics, 90 (1), pp. 103-115.
Perona M. Saccani N., 2004. “Integration techniques in customer-supplier relationships: an empirical research in the Italian industry of household appliances”, International Journal of Production Economics, 89 (2), pp. 189-205.
Perona M., Saccani N., Zanoni S., 2009. “Combining Make-to-Order and Make-to-Stock inventory policies: an empirical application to a manufacturing SME”, Production Planning and Control, 20 (7), pp. 559-575.
Porter M.E, 1985. Competitive Advantage: Creating and Sustaining Superior Performance, New York, the free press, Mc Millian.
Rgnier-Pcastaing F., Gabassi M., Finet J., 2013. Master Data Management, Springer Publishing Company, Incorporated.
Romanowski C.J., Rakesh N., 2004. “A data mining approach to forming generic bills of materials in support of variant design activities”, Journal of Computing and Information Science in Engineering, 4 (4), pp. 316-328.
Saccani N., Johansson P., Perona M., 2007. “Configuring the after-sales service supply chain: a multiple case study”, International Journal of Production Economics, 110 (1), pp. 52-69.
Saccani N., Perona M., 2007. “Shaping buyer-supplier relationships in manufacturing contexts: design and test of a contingency model”, Journal of Purchasing and Supply Management, 13 (1), pp. 26-41.
Secchi R., 2000. Produrre e gestire informazioni per integrare la supply chain, Milano, Guerini e Associati.
Son M.J., Lee S C., Kwon K.C., Kim T.W., Sharma R., 2011. “Configuration estimation method for preliminary cost of ships based on engineering bills of materials”, Journal of marine science and technology, 16 (4), pp. 367-378.
Spina G.L., Verganti R., Zotteri G., 2002. “Factors influencing co-design adoption: drivers and internal consistency”. International Journal of Operations & Production Management, 22 (12), pp. 1354-1366.
Spina G.L., Verganti R., Zotteri G., 2002. “A model of co-design relationships: definitions and contingencies”. International Journal of Technology Management, 23 (4), 304-321.
Stefansson G., Tilanus B., 2001. “Tracking and tracing: principles and practice”.International Journal of Services Technology and Management, 2 (3-4), pp. 187-206.
Thalheim B., 2013. Entity-relationship modeling: foundations of database technology.Springer Science & Business Media.
Tersine R.J., 1994. Principles of Inventory and Materials Management, second edition,North Holland.
Terzi S., Bouras A., Dutta D., Garetti M., Kiritsis D., 2010. “Product lifecycle management: from its history to its new role”, International Journal of Product LifecycleManagement, 4 (4), pp. 360-389.
Valentini G., Zavanella L., 2003. “The consignment stock of inventories: industrial case and performance analysis”. International Journal of Production Economics, 81, 215-224.
Van Veen E.A., Wortmann J.C., 1992. “Generative bill of material processing systems.” Production Planning & Control, 3 (3), pp. 314-326.
Vilminko-Heikkinen R., Pekkola S., 2013. “Establishing an organization’s master data management function: a stepwise approach”. In: 46th Hawaii International Conference on System Sciences (HICSS), pp. 4719-4728.
Wacker J.G., Treleven M., 1986. “Component part standardization: an analysis of commonality sources and indices”. Journal of Operations Management, 6 (2), 219-244.
White A., Newman D., Logan D., Radcliffe, J., 2006. Mastering master data management.Gartner Group, Stamford.
Wight O., 1995. Manufacturing resource planning MRP II: unlocking America’s productivity potential. John Wiley & Sons.
Immagine fornita da Shutterstock.






